Your cart is currently empty!
Month: February 2021
-
Personalized Marketing With Chatbots in 2021
Chatbots, the saviors during the pandemic which helped companies to automate their customer support and marketing are still making headlines in the business world.
Thanks to its limitless use cases and benefits, they have come a long way from just a replacement for quick replies to automating the entire marketing operations, cutting costs and increasing revenue, helping the customers to get a better and more fun experience and a lot more.
The last few years and especially the last few months have witnessed high adoption of chatbots into the business world with an estimation of $5 billion being invested in it.

Personalized chatbots are making their ways into every brand, and here’s why you should use them too:
Personalize User Experience With Chatbots
While in general, a chatbot’s answers are only based on their pre-programmed conversational flow for all kind of users.
However personalizing chatbots makes them capable to understand the customers, ask questions like a human, enabling them to sense patterns, and a lot more to determine every customer’s interests and gives relevant suggestions. Hence, filling the gap between a brand and its customers. Making the interaction for customers with chatbot a lot more humane than just another boring bot conversation.
Trending Bot Articles:
4. How intelligent and automated conversational systems are driving B2C revenue and growth.
“As the experience is taken care of at a personal level, it may also increase the conversion rates. Bonus!”
Generate Leads, Drive Engagement
Chatbots are extremely useful and valuable for generating and driving leads, as they offer a way to interact with customers at scale, answer their queries instantly, simplify product discovery, guide through, and add suggestions.
Nobody wants to talk to a robot that understands nothing, do you?
Chatbots are good at serving customers, however, personalizing a chatbot with graphical and humanoid elements makes them better at doing their job. Also, it makes them capable to serve every human engagement in different ways. If your conversational flow is personalized and knows how to interact with every lead, it makes a lot of difference.
A personalized chatbot can offer users a better experience with its “personalized conversational messages and graphics”, which can be a sales magnet for your business. If you can connect with users and sync with their thoughts, you can easily alter the nature of a conversation. As a result of it, you may see users who were not planning to make a purchase initially turn out to give you good business.
The only challenge that you may face in getting such results is designing a good conversational flow. For that, you can use personalized marketing tools, there are many out there offering chatbot integration.
“Reports show that a customer engages at least 30% more with the brand, and spends 20% — 40% more time on the platform if the chatbot sounds like a human to them.”
Get “Even” Better ROI
Chatbots are indeed a kind of expensive sometimes. However, when we see the long-term benefits and the returns on investments, it indisputably gives better numbers.
Every 6 of 10 enterprises agree that chatbots may come at a high expense initially, (which can be ignored) but if we look at how much it improves customer engagement, lead generation process, user experience, and e-commerce optimization, they worth every bit of it.
With personalized conversational flow in a chatbot (that offers seamless and human-like responses to every customer) can make users almost feel bot as a human. It helps businesses to acquire customers smoothly at lower costs. Additionally, this also reduces the costs related to business operations, marketing, and customer retention.
Get Customer Analytics & Insights
Probably the biggest advantage of having a chatbot over humans is that it gives the inside access to a customer’s thoughts and behaviors using data.
Over the time of operation, chatbots interact with many customers from different backgrounds and collect respective data for the same. The same data can be analyzed to have insights and determine the customer behavior and use that to optimize the conversational flow to improve personalization.
Designing a conversational flow takes a lot of effort, especially if it is designed for personalizing a chatbot. Every message, image, animated banner, and video you are creating for it should have the capability to deliver the right message and engage the audience. It may take hours to design personalized flows, but it is worth every minute.
Enhance The Shopping Experience
Reports show that 8 out of 10 new online shoppers require additional support for making purchases. These may range between navigating through the website, explaining the various products, checking out, making payments, checking the order and delivery status, etc. Hence, guiding these new customers becomes the priority.
Personalized chatbots act as a shopping guide for these new customers. It not only helps them but also acts as if they are a companion, understand customers, and suggest products, and this makes customers more likely to engage and purchase.
Create & Build Brand Loyalty
If we follow reports, every 5 in 10 persons say they will purchase again from a brand that treats them well.
Since personalized chatbots act as actual human begins, enhances a customer’s shopping experience, solve their queries, it creates a good impression within a customer’s mind and develops a relationship with the customer.
And nothing makes customers happier than being valued high, and this instantly makes them loyal to a brand for the fact it treated the person well.
Wrapping Up!
Chatbots help to generate and convert leads, enhance the shopping experience, personalize the experience, get inside data, create loyalty, and a hell of a lot more!
It offers so many benefits that it becomes hard to count. And on top of that, it also collects and provides tons of data to the business owners that paves the way and makes the room for future development for the business.
If you are not leveraging personalized chatbots to make get sales out of it yet in today’s world, you are making a mistake and missing out on an enormous opportunity.
Don’t forget to give us your 👏 !



Personalized Marketing With Chatbots in 2021 was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.
-
Warum RPA und Chatbots die ideale Lösung für die Automatisierung von Einkaufsprozessen sind
Einkaufsabteilungen sehen sich immer wieder mit einer großen Frage konfrontiert: Wie können wir die Kosten senken und Prozesse effizienter gestalten?
Viele Tätigkeiten im Einkauf sind repetitiv und folgen einem klar definierbaren Ablauf. Daher bietet es sich an diese mit Bots zu automatisieren. So können Prozesse effizienter gestaltet und die Mitarbeiter entlastet werden. Nur für welche Art von Bot sollten Einkaufsabteilungen sich entscheiden? Chatbots? RPA Bots? Oder ist eine Kombination beider Technologien besser?
In diesem Blog Artikel erfährst du:
- Was RPA Bots und Chatbots sind
- Worin die Technologien sich unterscheiden
- Warum sie als Team die ideale Lösung für Einkaufsprozesse sind
Was ist der Unterschied zwischen Chatbots und RPA?
Vereinfacht gesagt, ist der Unterschied zwischen Chatbots und RPA Bots, dass Chatbots menschliche Kommunikation und RPA Bots menschliche Handlungen nachahmen.
Was ist ein Chatbot und was kann er?
Ein Chatbot ist eine Technologie, mit der Nutzer mittels natürlicher Sprache kommunizieren können. Dabei können die Nutzer per Texteingabe sich dem Chatbot mitteilen und Fragen stellen. Die Fragen der Nutzer kann der Chatbot mit Hilfe von Natural Language Processing ( NLP) Services verarbeiten, verstehen und automatisiert beantworten.
Chatbots sind besonders dafür geeignet Informationen rund um die Uhr schnell bereit zu stellen. So kann ein Mitarbeiter aus dem Einkauf zum Beispiel einen Chatbot fragen, wie lange der Vertrag mit einem bestimmten Lieferanten noch läuft.
Was ist RPA (Robotic Processing Automation) und was steckt dahinter?
Bei Robotic Processing Automation werden repetitive, manuelle, zeitintensive oder fehleranfällige Tätigkeiten durch Bots erlernt und automatisiert ausgeführt. Diese Prozesse folgen festen Regel und Strukturen. So kann zum Beispiel das massenhafte Eintragen von Nummern in Formulare durch RPA Bots automatisiert werden.
RPA Bots bieten den Vorteil, dass sie die Tätigkeiten rund um die Uhr automatisiert erledigen und im Gegensatz zu Menschen keine Flüchtigkeitsfehler machen oder unkonzentriert werden.
Wann macht ein RPA Bot und wann ein Chatbot Sinn?
Der Einsatz eines RPA Bots macht Sinn, wenn Prozesse automatisiert ohne eine Interaktion mit Menschen abgewickelt werden sollen. Diese Prozesse müssen innerhalb fester Strukturen und regelbasiert ablaufen. Zudem müssen die Daten bereits digitalisiert vorliegen.
Bei einem RPA Bot gibt es kein Chat Element, mit welchem die Nutzer sich mit dem Bot austauschen können. Ein RPA Bot kann auch nicht eigenständig auf Veränderungen reagieren. Er führt den Prozess immer gleich aus.
Ein Chatbot ist hingegen flexibel und nutzerzentriert. Er kann auf das unterschiedliche Verhalten der Nutzer reagieren und dabei spontan auf die nächste Frage antworten. Der Nutzer ist nicht gezwungen einen bestimmten Prozess immer in derselben Reihenfolge zu durchlaufen. So können Mitarbeiter:innen der Einkaufsabteilung zuerst nach einer Lieferantennummer und dann nach der Bestellmenge fragen. Der Chatbot wäre aber auch in der Lage die Fragen zu beantworten, wenn zuerst nach der Bestellmenge und dann erst nach der Lieferantennummer gefragt wird.
Zudem besteht bei einem Chatbot die Möglichkeit das Gespräch einem echten Mitarbeiter zu übergeben. Diesen Vorgang nennt man Human Handover. Er wird eingeleitet, wenn der Chatbot nicht weiter weiß oder der Nutzer um den Kontakt mit einem echten Menschen bittet.
Wie RPA und Chatbots gemeinsam ihr volles Potenzial entfalten können
Ihr volles Potenzial können beide Arten von Bots entfalten, wenn sie miteinander kombiniert werden. Hierbei fungiert der Chatbot sozusagen als Front End für den RPA Bot. Wenn ein Mitarbeiter einen automatisierten Prozess auslösen möchte, beginnt er ein Gespräch mit dem Chatbot. Der Chatbot sammelt alle nötigen Informationen, indem er dem Mitarbeiter Fragen stellt. Diese Informationen werden dann von dem Chatbot an den RPA Bot übermittelt und der automatisierte Prozess wird ausgelöst.
Ein einfaches Beispiel hierfür ist ein Bestellvorgang:
- Ein Mitarbeiter möchte Produktionsmaterialien bestellen.
- Er kontaktiert den Chatbot und teilt ihm mit, dass er eine Bestellung aufgeben möchte.
- Der Chatbot erfragt die notwendigen Informationen wie die Lieferantennummer, Stückzahl, etc. und gibt diese an den RPA Bot weiter.
- Der Bestellprozess wird ausgelöst und abgewickelt.
- Im Nachgang kann der Mitarbeiter den Chatbot nutzen, um nach dem aktuellen Stand der Lieferung zu fragen.
Weitere Beispiele, wie Chatbots kombiniert mit RPA im Einkauf eingesetzt werden können, findest du in unserem White Paper “How to use Chatbots in Procurement”.

Der Beitrag Warum RPA und Chatbots die ideale Lösung für die Automatisierung von Einkaufsprozessen sind erschien zuerst auf BOTfriends.
-
Top 6 Customer Experience Trends For 2021
In a nutshell, customer experience directly influences purchasing decisions and a brand’s revenue in 2021. With that in mind, here are some trends to consider, to deliver powerful customer experiences in 2021. https://botcore.ai/blog/customer-experience-trends-for-2021/
submitted by /u/Sri_Chaitanya
[link] [comments] -
Hands-on for Toxicity Classification and minimization of unintended bias for Comments using…
Hands-on for Toxicity Classification and minimization of unintended bias for Comments using classical machine learning models
In this blog, I will try to explain a Toxicity polarity problem solution implementation for text i.e. basically a text-based binary classification machine learning problem for which I will try to implement some classical machine learning and deep learning models.
For this activity, I am trying to implement a problem from Kaggle competition: “Jigsaw Unintended Bias in Toxicity Classification”.
In this problem along with toxicity classification, we have to minimize the unintended bias (which I will explain briefly in the initial section).

source Business problem and Background:
Background:
This problem was posted by the Conversation AI team (Research Institution) in Kaggle competition.
This problem’s main focus is to identify the toxicity in an online conversation where toxicity is defined as anything rude, disrespectful, or otherwise likely to make someone leave a discussion.
Conversation AI team first built toxicity models, they found that the models incorrectly learned to associate the names of frequently attacked identities with toxicity. Models predicted a high likelihood of toxicity for comments containing those identities (e.g. “gay”).
Unintended Bias
The models are highly trained with some keywords which are frequently appearing in toxic comments such that if any of the keywords are used in a comment’s context which is actually not a toxic comment but because of the model’s bias towards the keywords it will predict it as a toxic comment.
For example: “I am a gay woman”

Problem Statement
Building toxicity models that operate fairly across a diverse range of conversations. Even when those comments were not actually toxic. The main intention of this problem is to detect unintentional bias in model results.
Constraints
There is no such constraint for latency mentioned in this competition.
Evaluation Metrics
To measure the unintended bias evaluation metric is ROC-AUC but with three specific subsets of the test set for each identity. You can get more details about these metrics in Conversation AI’s recent paper.
Trending Bot Articles:
4. How intelligent and automated conversational systems are driving B2C revenue and growth.
Overall AUC
This is the ROC-AUC for the full evaluation set.
Bias AUCs
Here we will divide the test data based on identity subgroups and then calculate the ROC-AUC for each subgroup individually. When we select one subgroup we parallelly calculate ROC-AUC for the rest of the data which we call background data.
Subgroup AUC
Here we calculate the ROC-AUC for a selected subgroup individually in test data. A low value in this metric means the model does a poor job of distinguishing between toxic and non-toxic comments that mention the identity.
BPSN (Background Positive, Subgroup Negative) AUC
Here first we select two groups from the test set, background toxic data points, and subgroup non-toxic data points. Then we will take a union of all the data and calculate ROC-AUC. A low value in this metric means the model does a poor job of distinguishing between toxic and non-toxic comments that mention the identity.
BNSP (Background Negative, Subgroup Positive) AUC
Here first we select two groups from the test set, background non-toxic data points, and subgroup toxic data points. Then we will take a union of all the data and calculate ROC-AUC. A low value in this metric means the model does a poor job of distinguishing between toxic and non-toxic comments that mention the identity.
Generalized Mean of Bias AUCs
To combine the per-identity Bias AUCs into one overall measure, we calculate their generalized mean as defined below:

source: Jigshaw competition evaluation metric Final Metric
We combine the overall AUC with the generalized mean of the Bias AUCs to calculate the final model score:

source: Jigshaw competition evaluation metric Exploratory Data Analysis
Overview of the data
“Jigsaw provided a good amount of training data to identify the toxic comments without any unintentional bias. Training data consists of 1.8 million rows and 45 features in it.”

“comment_text” column contains the text for individual comments.
“target” column indicates the overall toxicity threshold for the comment, trained models should predict this column for test data where target>=0.5 will be considered as a positive class (toxic).
A subset of comments has been labeled with a variety of identity attributes, representing the identities that are mentioned in the comment. Some of the columns corresponding to identity attributes are listed below.
- male
- female
- transgender
- other_gender
- heterosexual
- homosexual_gay_or_lesbian
- Christian
- Jewish
- Muslim
- Hindu
- Buddhist
- atheist
- black
- white
- intellectual_or_learning_disability
Let’s see the distribution of the target column
First I am using the following snippet of code to convert target column thresholds to binary labels.

Now, let’s plot the distribution
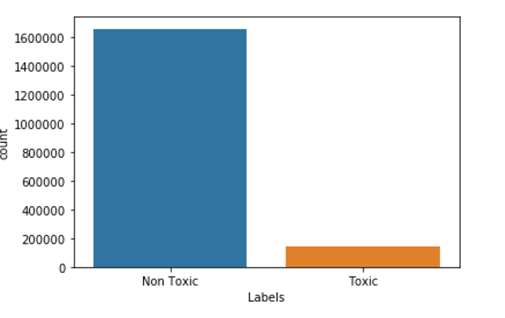
Distribution plot for Toxic and non Toxic comments We can observe from the plot around 8% of data is toxic and 92% of data is non-toxic.
Now, let’s check unique and repeated comments in “comment_text” column also check of duplicate rows in the dataset
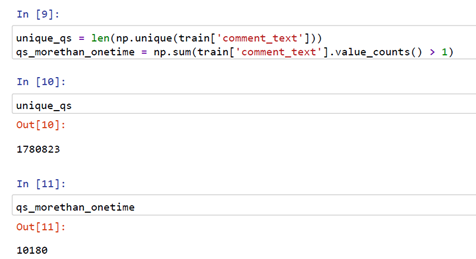
From the above snippet, we got there are 1780823 comments that are unique and 10180 comments are reaping more than once.
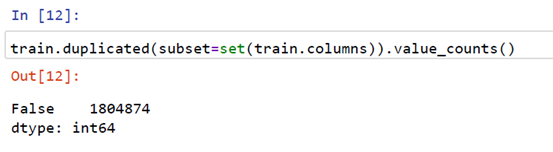
So we can see in the above snippet there are no duplicate rows in the entire dataset.
Let’s Plot box Plot for Non-Toxic and Toxic comments based on their lengths
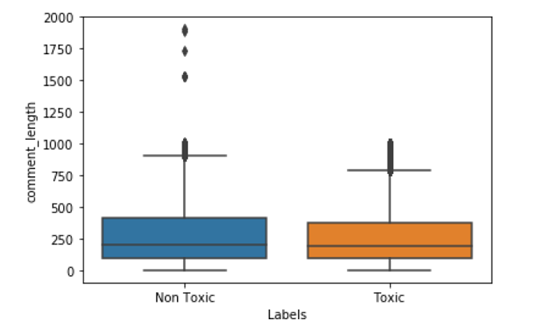
Box plot for Toxic and non Toxic comments From the above plot, we can observe that most of the points for toxic and non-toxic class comments lengths distributions are overlapping but there are few points in the toxic comments where comment length is more than a thousand words and in the non-toxic comment, we have some point’s are more than 1800 words.
Let’s quickly check the percentile for comment lengths
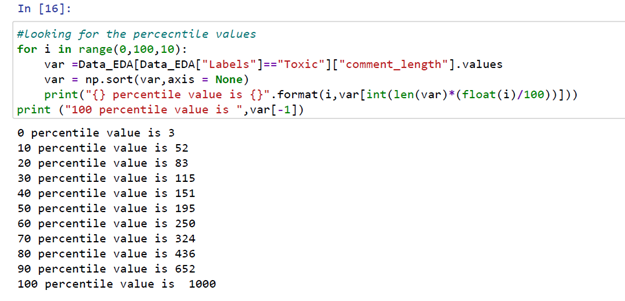
From the above code snippet, we can see the 90th percentile for comment lengths of toxic labels is 652 and the 100th percentile comment length is 1000 words.
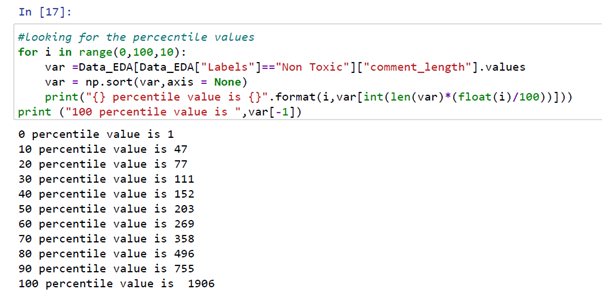
From the above code snippet, we can see the 90th percentile for comment lengths of non-toxic labels is 755 and the 100th percentile comment length is 1956 words.
We can easily print some of the comments for which comment has more than 1300 words.

Let’s plot Word cloud for Toxic and Non-Toxic comments
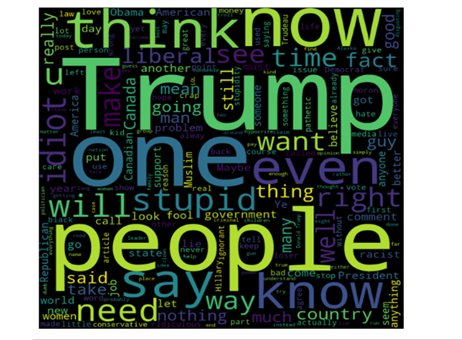
word cloud plot for Toxic comments In the above plot, we can see words like trump, stupid, ignorant, people, idiot used in toxic comments with high frequency.

word cloud plot for Non-Toxic comments In the above plot, we can see there are no negative words with the high frequency used in non-toxic comments.
Basic Feature Extraction
Let us now construct a few features for our classical models:
- total_length = length of comment
- capitals = number of capitals in comment
- caps_vs_length = (number of capitals in comment)
- num_exclamation_marks = num exclamation marks
- num_question_marks = num question marks
- num_punctuation = Number of num punctuation
- num_symbols = Number of symbols (@, #, $, %, ^, &, *, ~)
- num_words = Total numer of words
- num_unique_words = Number unique words
- words_vs_unique = number of unique words/number of words
- num_smilies = number of smilies
- word_density = taking average of each word density within the comment
- num_stopWords = number of Stopwords in comment
- num_nonStopWords = number of non Stopwords in comment
- num_nonStopWords_density = (num stop words)/(num stop words + num non stop words)
- num_stopWords_density = (num non stop words)/(num stop words + num non stop words)
To check the implementation of these features you can check my EDA notebook.
After the implementation of these features let’s check the correlation of extracted feature with target and some of the other features form the dataset.
So for correlation first I implemented the person correlation of extracted features with some of the features from the dataset and plotted the following the seaborn heatmap plot.
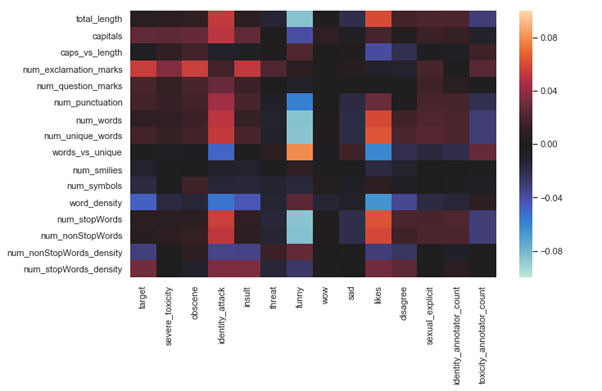
Correlation plot between extracted features and some features in the dataset From the above plot, we can observe some good correlations between extracted features and existing features, for example, there is a high positive correlation between target and num_explation_marks, high negative correlation between num_stopWords and funny comments and we can see there are lots of features where there is no correlation between them, for example, num_stopWords with Wow comments and sad comments with num_smilies.
Feature selection
I applied some feature selection methods on extracted features like Filter Method, Wrapper Method, and Embedded Method by following this blog.
Filter Method: In this method, we just filter and select only a subset of relevant features, and filtering is done using the Pearson correlation.
Wrapper Method: In this method, we have to use one machine learning model and will evaluate features based on the performance of the selected features. This is an iterative process but better accurate than the filter method. It could be implemented in two ways.
1. Backward Elimination: First we feed all the features to the model and evaluate its performance then we eliminate worst-performing features one by one till we get some good relevant performance. It uses pvalue as a performance metric.
2. RFE (Recursive Feature Elimination): In this method, we recursively remove features and build the model on the remaining features. It uses an accuracy metric to rank the feature according to their importance.
Embedded Method: It is one of the methods commonly used by regularization methods that penalize a feature-based n given coefficient threshold of the feature.
I followed the implantation from this blog and used the Lasso regularization. If the feature is irrelevant, lasso penalizes its coefficient and make it 0. Hence the features with coefficient = 0 are removed and the rest is taken.
To understand these methods and its implementation more briefly please check this blog.
After implementing all the methods of feature selection I selected the results of the Embedded Method and will include selected features in our training.
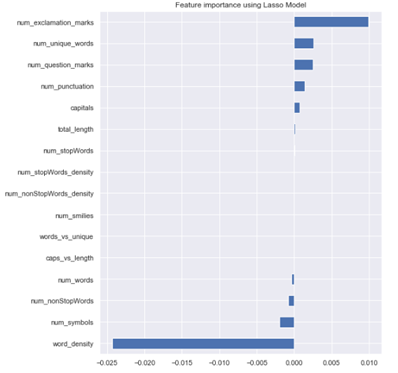
Results of embedded method Embedded method mark the following features as unimportant
1. caps_vs_length
2. words_vs_unique
3. num_smilies
4. num_nonStopWords_density
5. num_stopWords_density
I plotted some of the selected extracted features as the following plots:
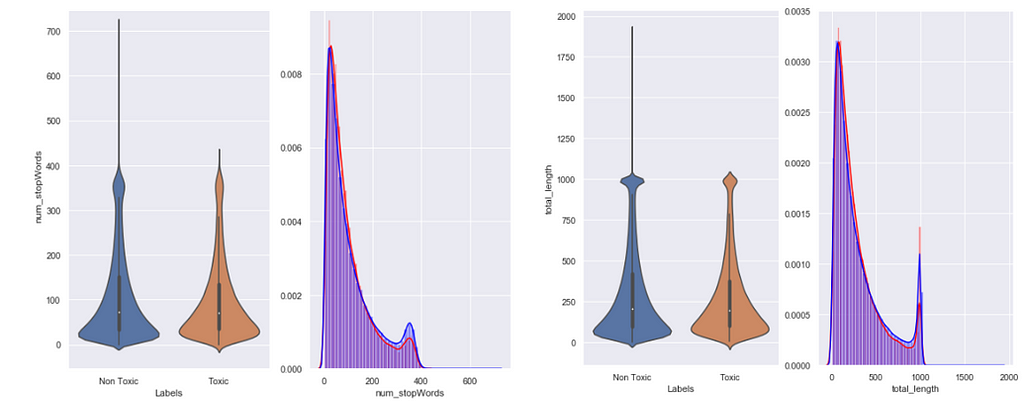
Violin plots 2 selected features Summary of EDA analysis:
1. The number of Toxic comments is less than Non Toxic comments i.e. 8 percent of toxic 92 percent of non-toxic.
2. We printed the percentile values of length of comments and observed the 90th percentile value is 652 for the Toxic and 90th percentile value is 755 for non-Toxic. We also checked there are 7 comments with length more than 1300 and all are non-toxic.
3. We created some text features and plotted the correlation table with Target and Identities Features. We also plotted the correlation table between extracted features Vs extracted features, to check correlation among them.
4. We applied some feature selection methods and used the results of Embedded Method where out of 16 we selected 11 as relevant features.
5. We plotted the Villon and Density plot for some of the extracted features with target labels.
6. We plotted Word cloud for Toxic and Non-Toxic comments and observed some words which are frequently used in Toxic comments.
Now let’s do some basic pre-processing on our data
Checking for NULL values

Number of null values in features From the above snippet, we can observe there is a lot of identity numerical features with lots of null values and there are no null values in comment text feature. Identity numerical features values are thresholds between 0 to1 along with target columns.
So, I converted the identity features along with the target column as Boolean features as mentioned in competition. Values greater than equal to 0.5 will be marked as True and other than that as False (null values now become False).
In the below snippet I selected few Identity features for our model’s evaluation and converting them to Boolean features along with the target column.
As the target column is binary now our data is ready for binary classification models.
Now I split the data into Train and Test in 80:20 ratio:

For text pre-processing, I am using the following function in which I am implementing
1. Tokenization
3. Stop words removal
4. Applying Regex to remove all non-words token and keeping all special symbols that are commonly used in comments.

Function to preprocess comment texts Vectorizing Text with Tf Idf Vectorize
As models can’t understand text directly, we have to vectorize our data. So to vectorize our data I selected TfIdf.
To understand TfIdf and its implementation in python briefly you can check this blog.
So, first, we are applying TfIdf on our train data with maximum features as 10000.

In TfIdf I got the scores for all tokens based on term frequency and inverse document frequency.
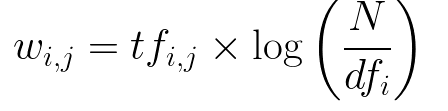
source: TfIdf weightage for a token Higher the score more weightage of the token.
In the following snippet, I collected the tokens along with the TfIdf score in tuples and stored all sorted tuples on the list.
Now based on the scores I selected 150 as threshold and now I will collect all tokens from TfIdf with score greater than 150.
In the following function, I am removing all tokens having a TfIdf score of less than 150.
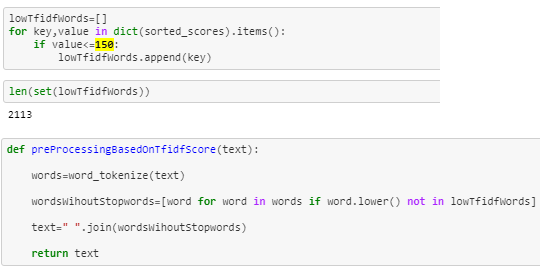
Selecting tokens with TfIdf score greater than 150 Standardization of numerical features
To normalize the extracted numerical features I am using sklearn’s StandardScaler which will standardize the numerical features.
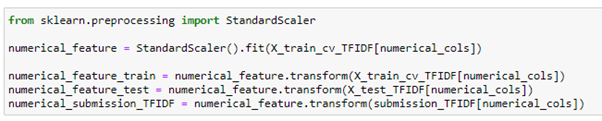
As I pre-processed the numerical extracted features and text feature lets now stack them using scipy’s hstack as follows:
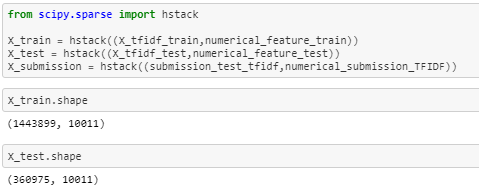
Now our data is ready so let’s start implementing some classical models on it.
Classical models:
In this section I will show you some Classical Machine Learning implementation, to check the implementation of all the classical models you can check my notebook.
Logistic Regression:
Logistic Regression one of the popular classification problems. There is a lot of applications that can be applied using a logistic regression classifier for binary classification problems like spam email filter detection, online transaction fraud or not, etc. Now I will apply logistic regression on the pre-processed stacked data.
To know more about logistic regression you can check this blog.
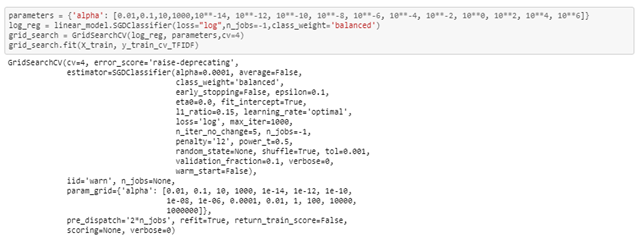
In the below snippet you can see I am using sklearn’s GridsearchCV to tune the hyperparameters, I choose value 4 for k cross-validation. Cross validations basically used to evaluate trained models with the different values of hyperparameters.
I am using different values of alpha’s get the best score. For alpha value 0.0001 I am getting the best score on CV based on GridSearchCV results.
Next, I trained a logistic regression model with the selected hyperparameter values on trained data, then I used the trained model to predict probabilities on test data.
Now I passed the data frame containing Identities columns along with logistic regression probability scores to Evaluation metric function.
You can see the complete implantation of the evaluation metric in this Kaggle notebook.
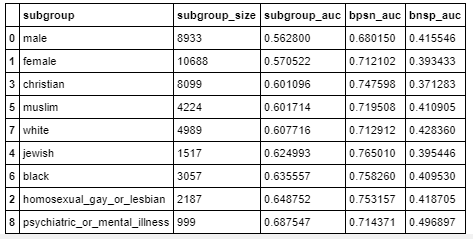
LR Classifier scores for all 3Evaluation parameters Evaluation metric score on test data: 0.57022
On preprocessing text and numerical features on competition’s train data I preprocessed the submission data as well. Now using the trained model I got probability scores for Submission data as well. Now I prepared submission.csv as mentioned in the competition.
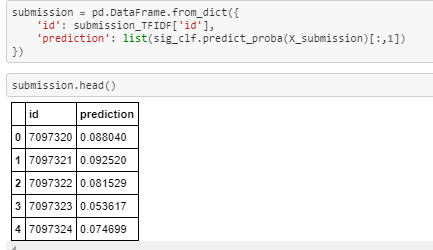
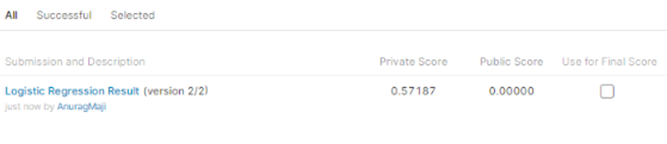
submission file preparation On submitting the submission.csv I got Kaggle score of 0.57187
Kaggle submission score for LR classifier Now following the same procedure, I trained all classical models. Please check the following table for the scores of all classification models I implemented.
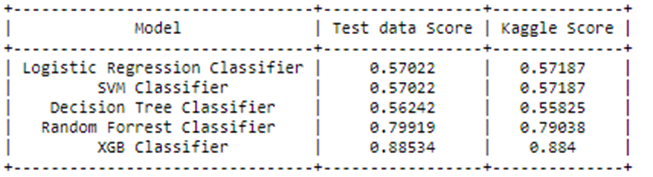
Classical models Scores So, the XGB classifier gives the best Evaluation metric and test score among all Classical models.
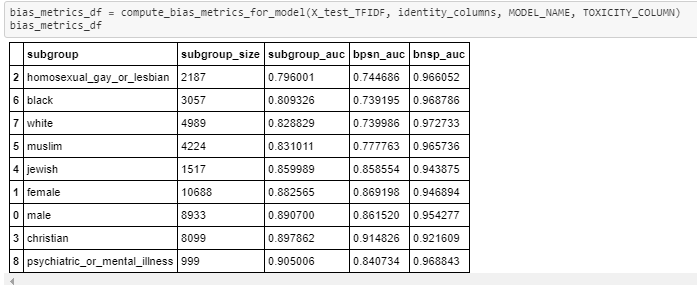
XGB Classifier scores for all 3 Evaluation parameters 
Kaggle submission Score for XGB classifier Please check part 2 of this project’s blog which explains the deep learning implementations and deployment function of this problem. You can check the implementation of EDA and classical machine learning models notebook on my Github repository.
Future work
Can apply deep learning architectures which can improve the model performance.
References
- https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification
- https://www.kaggle.com/nz0722/simple-eda-text-preprocessing-jigsaw
- Paper provided by Conversation AI team explaining the problem and metric briefly https://arxiv.org/abs/1903.04561
- https://www.appliedaicourse.com/
- https://towardsdatascience.com/feature-selection-with-pandas-e3690ad8504b
Don’t forget to give us your 👏 !
Hands-on for Toxicity Classification and minimization of unintended bias for Comments using… was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.
-
Alexa Answers Crowdsourcing Arrives in the UK

Amazon has extended its voice-based data publicly supporting Alexa Answers to the United Kingdom. The feature asks the overall population…
-
Amazon Alexa Skill Growth Has Slowed Further in 2020

In July of 2019, information showed Alexa aptitude development was easing back in most worldwide business sectors. It wasn’t clear to…
-
Why does your Business need a WhatsApp Chatbot?
With WhatsApp becoming a standard communication platform for personal and professional usage, businesses and new ventures are looking forward to adding this as a significant marketing and business operating platform. Here is a detailed analysis on “why does your business need a WhatsApp chatbot?”
submitted by /u/botpenguin1
[link] [comments]










