
Checkers and Rally’s have started to install a voice assistant in their drive-thru restaurants to assist their customers digitally. The…
Category: Chat
-
What’s the big deal about just-in-time learning? Here’s everything you need to know.

By now, most of us know that every learner requires different approaches to learning. There are many newer-age teaching methods including flipped learning, universal design for learning, and blended learning design.
The future of education is here and it brings countless new learning trends in 2022.
With our constantly-changing environment with regards to technology and the workforce, it’s not surprising that there are all sorts of new jobs (and even industries) that we’re hearing for the first time.
Not every student will follow the traditional path in their education or career, which is why relevant and specific industry skills and knowledge is highly valuable.
How can you equip students with targeted knowledge? That’s where just-in-time learning comes in.

-
MyBot/MyBot Creator
Does anyone remember and/or know what happened to the MyBot and MyBot Creator Apps? They seem to have just disappeared from the app store, and are no longer working even though I had downloaded them before they got removed from the app store.
submitted by /u/Electrical_Candy_425
[link] [comments] -
Voice Assistant “Kimi” starred as a Murder Witness in an Upcoming HBO max Film
HBO Max is ready to launch an intelligent AI-operated Voice Assistant, “Kimi” in an upcoming eponymous film. Angela Childs, played by Zoe…
-
Create chatbot using bot framework sdk and LUIS — Part 4
Create chatbot using bot framework sdk and LUIS — Part 4
In the previous 3 parts we created a simple e-comm chatbot, we completed the create order conversation flow. Saved the order details in a csv. In this part we will be adding intelligence to our bot using LUIS.
We will complete following steps in this part:
- Create a LUIS app. Train and publish the app.
- Use the app in our bot service.
- Update create order dialog to handle slot filling. that is detecting missing entities in the order details and ask user to provide the values for the required entities.
- Complete create order flow

Microsoft Azure LUIS:
Microsoft’s Azure LUIS is NLU service which is available on Azure. For using LUIS we create LUIS app. Add intents and entities in our app. We also provide sample user utterances for the intents.
For a given text, LUIS app first detects to which intent the given text belongs to. In simple word it takes the users requirement in user’s own words and then interprets it to understand what exactly user’s need is. It then extracts the important words from the user’s text, which we call entities. For exapmple — in our user case, user provides the order description in his own words. In the order descrption we need to find the word which tells the item name like cake or pastry etc. similarly word whcih tells the flavour of the item like chocolate, cheese etc. So in this example item name and flavour are the entities.
For more details check below links:
- Intents and entities – LUIS – Azure Cognitive Services
- Entity types – LUIS – Azure Cognitive Services
Why we need LUIS in our bot service?
We are asking user to provide the order description in his own words. The bot needs to understand whether tthe order consists of only one item or more than one item. If more than one item are there in the order that means we need to refer each order item details as sub order and create multiple line items which an order. Also for ech item bot has to check whether the order detail is com plete or not for example if cake is requested then is the size and flavour of the cake are provided by the user or not. For identifying sub-orders in the order description and the required details i.e. entities in the order description we need th Natural Language understanding service. LUIS is the Natural Language Service which we will be using in our bot.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Create a LUIS app using the JSON provided:
You need to create a LUIS app, for that you should have an azure account subscription. Follow the steps mentioned here to create LUIS App.
Intents and entities required for our bot is defined in the json here.
Copy this orderApp.json on your machine. we will be importing this json in the LUIS app to add the required intents and entities in the luis app.
To import the json in your luis app. Go to your luis app, and click on the down arrow next to New App button.
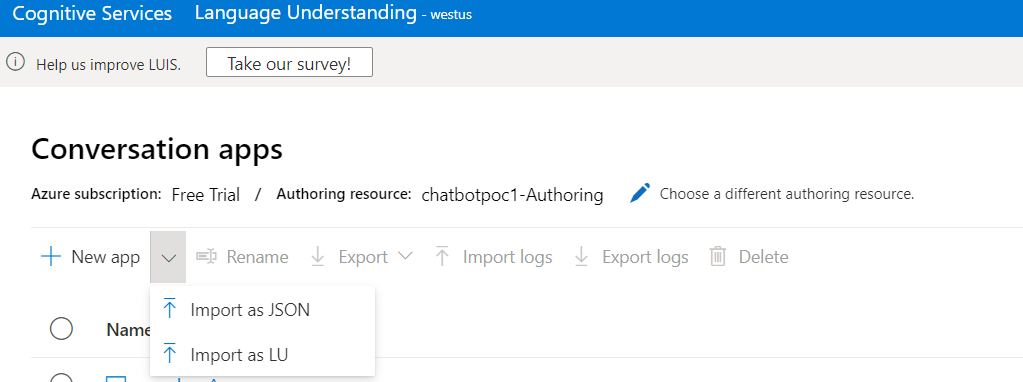
Now select Import as json and browse to ordersApp.json file. This creates the intents and entities in your app.
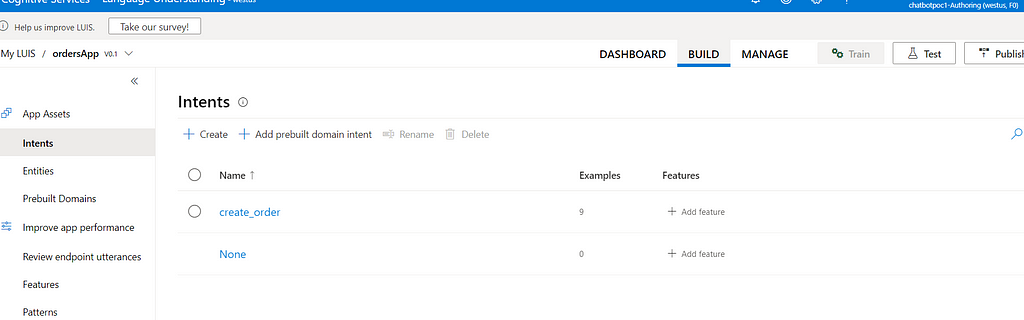
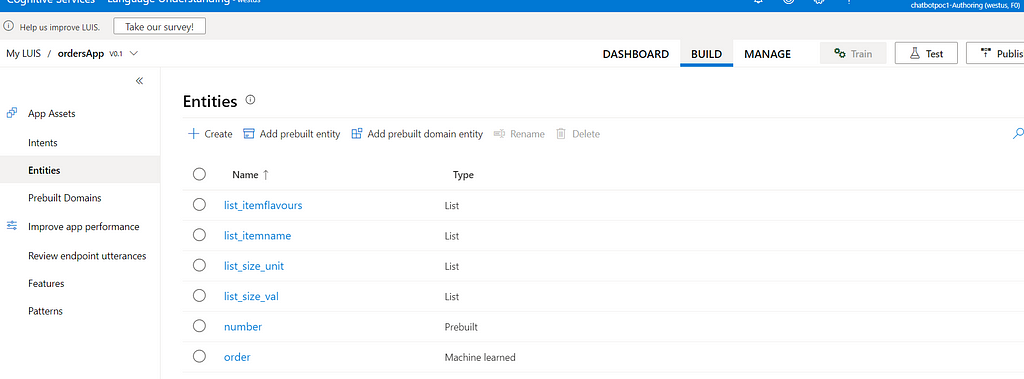
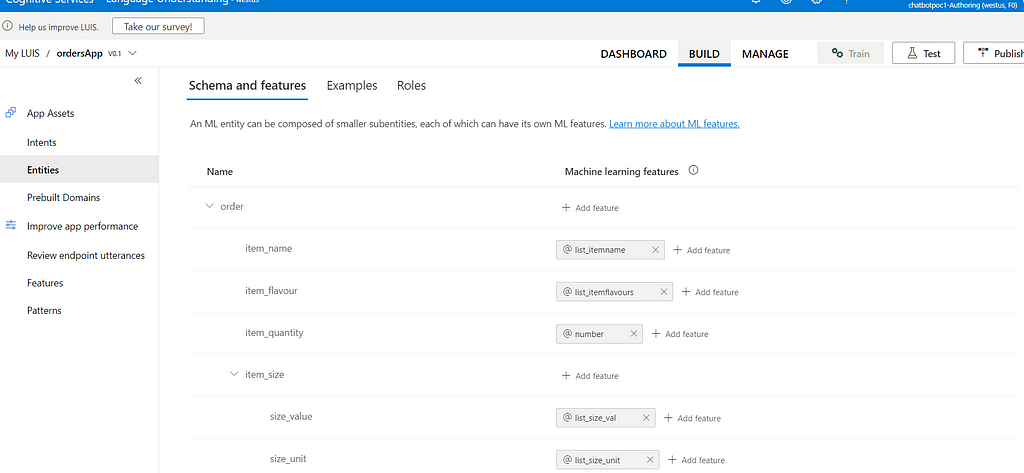
Order entity is a structured entity. Thre are sub-entities defined under the main order entity. Explore each entity to understand them clearly. Check utternces defined for create_order intent. See how order entity and other sub-entities are marked in the utterances. These are the training data. You can add more training data to improve accuracy. Click on the test tap to test the app.
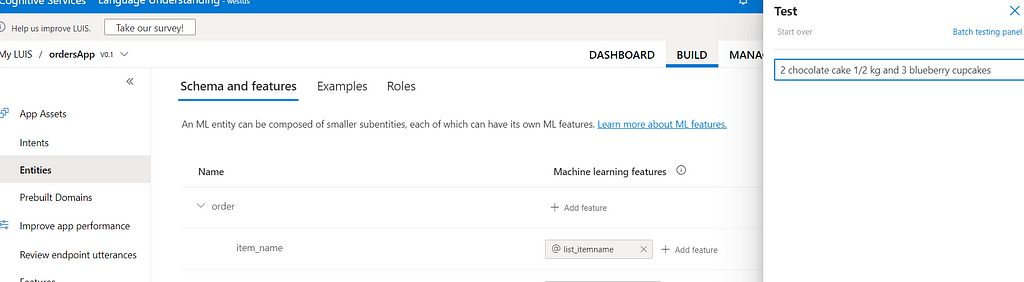
Above text returns below result, click on the inspect to see the detailed result. LUIS service has detected there are 2 orders in the given text. For each order it has identified the entities i.e. item_name, item_flavour etc. correctly. Expand item_size entity to check the values retrieved for size_unit and size_value entities. Our LUIS app is working prefectly!

Now we can publish the app. Click on the Publish button to publish the app. You will get 2 options Staging Slot and Production Slot. Select production slot. It will take few minutes to publish the app.
After the app is published, go to Manage tab. On Manage screen you will find “Azure Resources” option pane. Click on the “Azure Resources” option you will be on “Prediction Resources” tab. Copy the URL given in the Example Query. Add this URL in the config file or your project. Add a new attribute in config.py. Name the attribute “LUIS_APP_URL” set the value as the URL cpied from Azure Resources. Trim the text “YOUR_QUERY_HERE” from the URL (u will find this text at the end of the URL).
We will be using this URL to send the user provided order description text to the LUIS App.
Add LUIS App helper function:
Add a new script file luisApp.py and add the below code in it. Below code defnes a function that takes a text as input and pass it to the LUIS by concatenating the LUIS_APP_URL and the input text. The final URL is then invoked through get method. The reslt returned is a json which is then returned to the calling function.
Define class for sub-order details:
We will add a new class order_details.py in the project. This will have all order related attributes. Add below code in order_details.py
Add new attributes in user_details.py
In user_details we will add 2 new attributes orders_list and current_order. Orders_list is a list type attribute this will be used to maintain the list of sub-orders. current_order is int type attribute this is to keep track of the current sub-order while iterating through the sub-orders for chceking completeness of the su-orders.
Modify createorder_dialog to add new steps for LUIS call:
Open createorder_dialog.py add 2 new steps act_step and completeorder_step after order_step. Declare these new steps in the waterfall dialog in init function. Now we have to define these functions.
In act_steps, we will add code to accept the order description provided by the user. Pass this text to LUIS by calling getLuisResponse function of luisApp module. Now iterate through the “order” entities returned by luis. For each sub-order (or order entity) create an orderDetails object. Save the attributes/entities details obtained from Luis in the orderDetails object. Append this object in the orders_list. Add orders list in the context.
In completeorder_step start a new sub-dialog completeorder_dialog to check the completeness of each sub-orders.
We will create the new sub-dialog script after completing all the changes required in createorder_dailog.
We need to update summary_step as well. In the summary step we will add code to fetch the orders_list from the context object. Loop throgh each row and form the order description for each ro wby concatenating item name, quanity, flavour and size values.
Below is the updated createorder_dialog.py:
Add new sub-dialog completeorder_dialog:
Create a new dialog module in oprations folder. Add 4 waterfall steps — flavour_step, quantity_step, size_step and summary_step.
In the flavour step fetch the orders_list from the context. check if for the current_order (this attribute is set to 0 in createorder_dialog) index in orders_list, item_flavour attribute has value or not. If not then prompt user to provide the flavour name for the requested item. Otherwise proceed to the next step.
In the quantity_step fetch orders_list from context. Now check if any value is provided by the user, if yes then set the value as flavour for the the current_order in orders_list. Proceed to check if quantity value is provided or not. If not provided then prompt for the quantity else proceed to the next step.
In the size_step check if any new value is provided by the user, if yes then set it as quantity for the current_order in orders_list. Since size attribute is applicable for only item cake so this value is required only if the item_name is cake. Now check if the current_order item_name is Cake then check the size value, if provided then proceed to the next step else ask user to provide the size.
In the summary_step, check if any new value is provided by the user then set it as size value for the current order in orders_list. Now increase the current_order by 1. If current_order is greater than the length of the orders_list that means we have reached the end of the list hence end the dialog and go back to the createorder_dialog. Else continue completeorder_dialog from the first step.
Below is the code for completeorder_dialog:
Update App.py as we have added new sub-dialog:
With this we have completed coding for this part. In the next part we will complete view order and cancel order flow. We will now test the app using Bot Framework emulator. Refer to Part-1 for steps to run emulator.
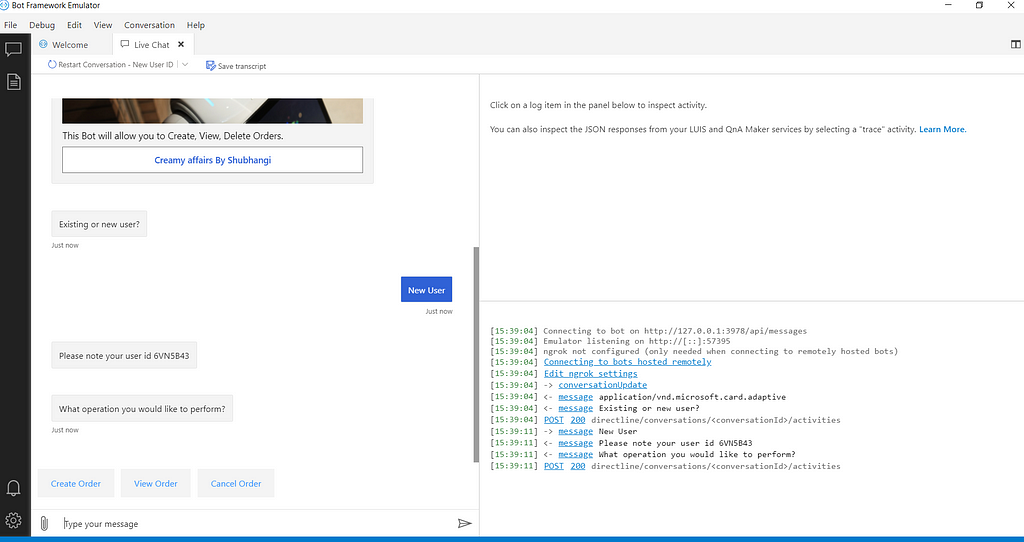
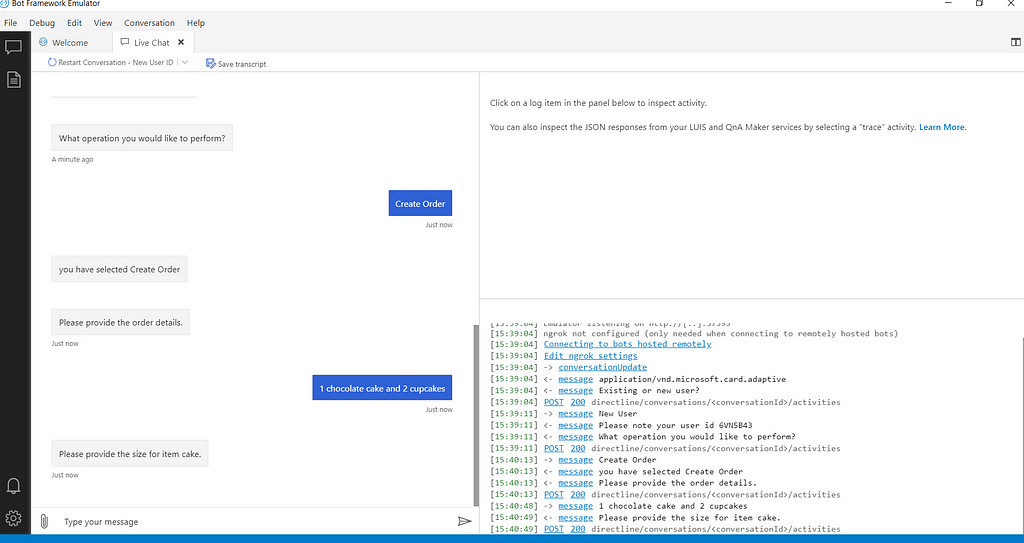
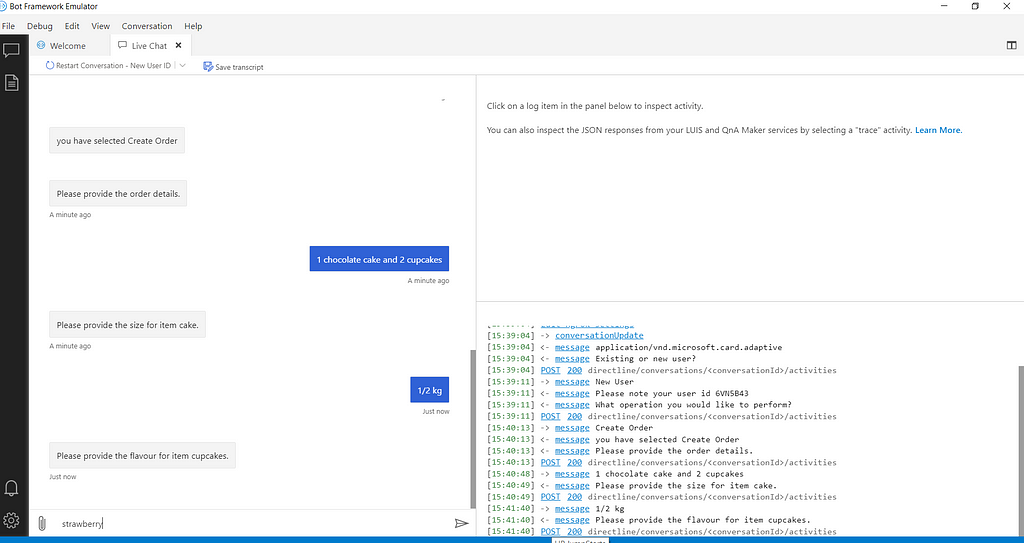

Important links:
Source Code — https://github.com/sushmita-mishra/e-comm-chatobot-luis
Don’t forget to give us your 👏 !



Create chatbot using bot framework sdk and LUIS — Part 4 was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.
-
Create chatbot using bot framework sdk and LUIS — Part 3
Create chatbot using bot framework sdk and LUIS — Part 3
In Part-1 and Part-2 we created a basic e-comm chatbot and started creating ‘create order’ conversation flow. In this part we will be generating order id and saving the order details in data storage. In next part we will be adding intelligence using LUIS. Complete source code is here.
Following tasks we will complete in this part:
- Generate order ID for the order details provided by the user
- Create a csv file to save the order details against the user id. (to keep this tutorial simple we r using csv for data storage, replace it with your database).

Create a csv file to store order details:
In the project folder add a new folder. Name it Data. Create a csv file order_dummy.csv with 5 columns — user_id, order_id, creation_date, order_status, order_description.
Create helper functions to manage order data:
Create a new python script orderApp.py in the project folder. We will be adding 3 functions — addOrders, viewOrders, cancelOrder. addOrders function is for adding the order details in csv, viewOrder function is for fetching order details of a given user id and cancel order is to update the order status to cancel for the given user id.
Copy below code in orderApp.py:
Update createorder_dialog to generate order id and save order details:
Open createorder_dialog.py, we will now update summary_step. Add code to generate a new order id. All order id’s will have prefix ‘ord’ followed by 4 digit random number.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Create a pandas dataframe. Add a record with the order details along with user id and order id. also set the order status to “Order Received”. Pass this dataframe to addOrder function of orderApp module.
Add bot response, show the newly generated order id to the user in the bot response.
Below is the updated createorder_dialog.py:
With this we have completed coding required for Part-3. Test your bot using bot frmaework emulator. Follwo the steps givin in Part 1, to run the emulator.
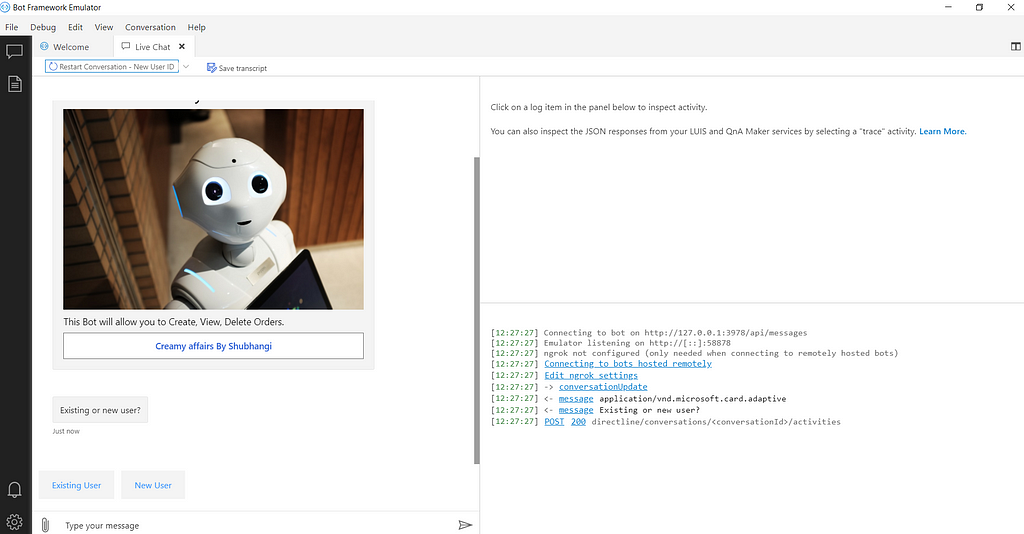
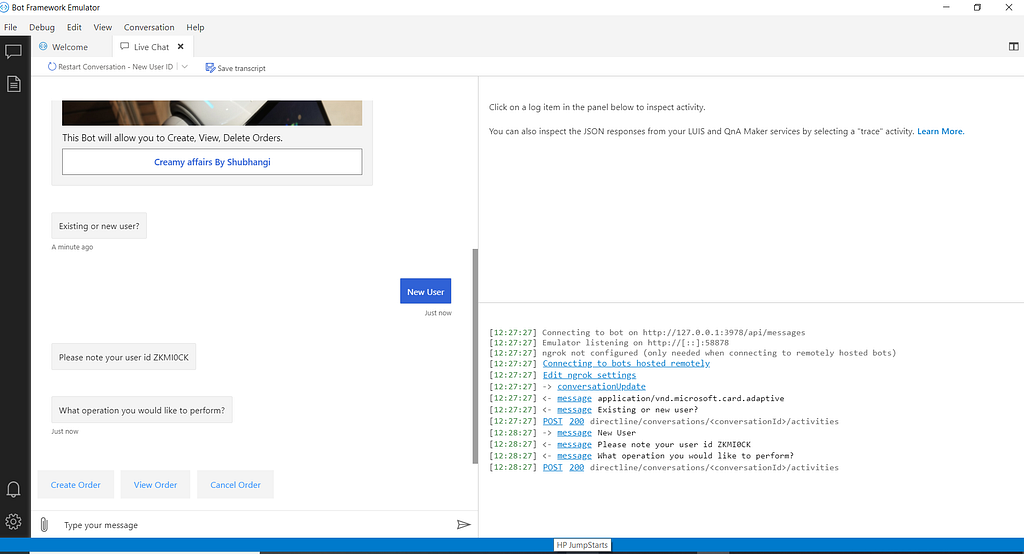
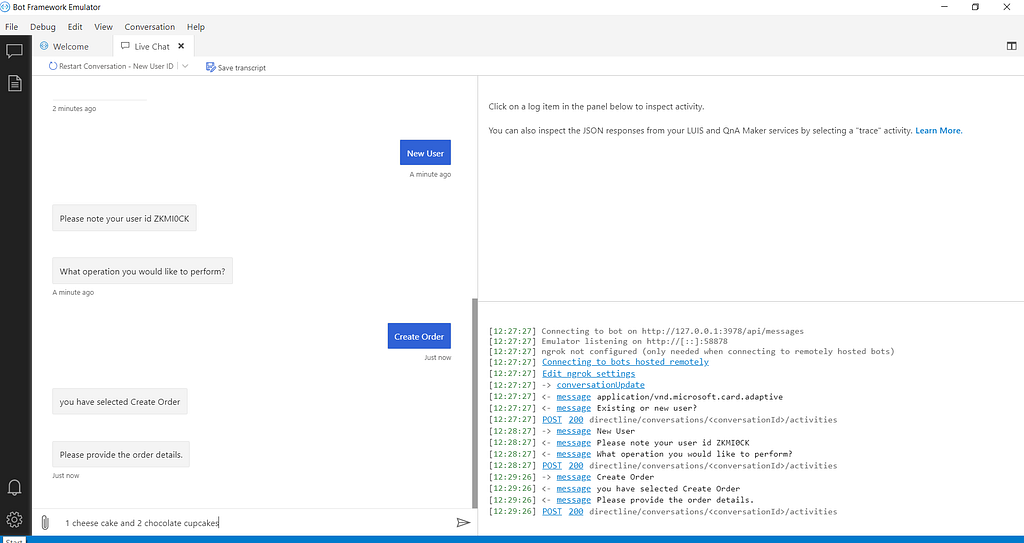
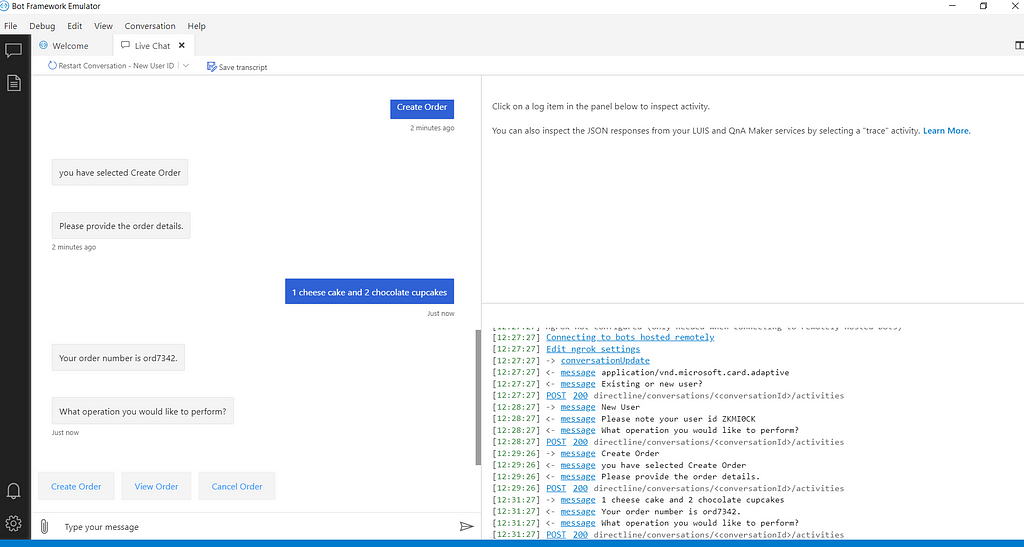
Try similar flow with existing user. Check the data saved in csv file.
See you in next part of the blog.
Important links:
Source code is here. Part-1 of the blog. Part -2.
Don’t forget to give us your 👏 !
Create chatbot using bot framework sdk and LUIS — Part 3 was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.
-
Emoji not appearing inside List in WhatsApp using Botpress

Greetings!
My gf is working on a chatbot project and is responsible for designing the phrases and its behaviours using the Botpress (https://botpress.com/) platform for WhatsApp API.Emojis usually appear in any circumstances with a simple copy-paste, but this does not happen when we talk about lists.
I’m posting as images two chatbot examples:
- the first one being the Netflix WhatsApp chatbot which has no issues at all while using emojis inside lists.
- The second, being her chatbot which simply refuses to display any pasted emojis in listings.
We already tried several things such as using the emoji’s Unicode but no success so far.
Any tips? As described, a simple copy-paste of the emojis themselves work just fine in any part of the bot, such as buttons, regular texts etc.
Thanks a lot!
submitted by /u/WilliamBenseny
[link] [comments] -
Knowing what your chatbots are talking about?
There’s a lot of analytics platforms that tell you about your bot’s performance, but what about just knowing what your users talk about with your bot? I’d imagine that’s especially useful for more open-ended, intelligent bots.
Are there tools that do this well? Why do people not really seem to talk about it (might just be because I’m a novice)?submitted by /u/winky334
[link] [comments] -
How many bots can you have in Botify ?
How many bots can you have in Botify ?
submitted by /u/hasoni1111
[link] [comments]



{kind=link}
{kind=link}