This article will show how to use TensorFlow Embedding Layers to implement a movie review text classification.

Processing Text Data
As we know, most machine learning algorithms cannot understand characters, words, or sentences. They can only take numbers as inputs. However, the nature of text data is unstructured and noisy, this characteristic makes it impossible to feed machine learning models directly with text data.
There are many ways to convert text data into numerical features, and the process to follow will depend on the kind of feature engineering technique selected.
One How Encoding
One of the most popular techniques for feature engineering is One Hot Encoding, this technique converts characters or words into binary numbers as we can see below.

With this technique, we will obtain a vector of size N (the size of the vocabulary) the vector is all zeros except for the ith entry, which is 1.
Count Vectorizing
The problem with One Hot Encoding is that all words will have the same importance not taking into account the number of occurrences of each word. The technique called Count Vectorization is similar to One Hot Encoding, but instead of checking if a particular word is present or not (0 or 1), it will consider the word count in a document.
However, this technique has some issues as well, for instance, words that are more frequent like “The, at, which, an …” don’t give much information. On the other hand, words that provide more information tend to be less frequent or rare. This issue is usually addressed using a technique called term-frequency time inverse document-frequency, which transforms a count vector into a sparse vector, taking into account the issue mentioned before.
Movie Review Text Classification Using scikit-learn
Using word vectors.
All the methods discussed depend on the frequency of the words, this approach can work in many scenarios, nevertheless, for complex tasks, it is necessary to capture the context of semantic relations, that is, how frequently the words are appearing close by. For example:
- I am eating an apple
- I am using apple
Despite the word “apple” appearing in both sentences, it gives different meanings when it is used with different adjacent words (close by). So the idea behind word embedding is to represent the meaning, semantic relationships, and different contexts in which the words are used.
Unlike vectors obtained through one-hot encoding or counting vectorization, word embeddings are learned from data this process turns out with a dense vector. Usually, these vectors are 256-dimensional, 512-dimensional or 1024 dimensional when we are dealing with large vocabularies. Contrarily with vectors obtained from one-hot encoding or counting vectors which are 20000 dimensional, or even greater (according to the vocabulary size) so word embedding provides more information in fewer dimensions.
One advantage of word embedding is that we can create specific word embeddings for specific tasks. This aspect is important because the perfect word embedding space for an English-Language movie-review sentiment-analysis model might be far away from the perfect embedding space for an English-Language legal-document-classification model. After all, semantic relationships vary from task to task.
Implementing Word Embeddings with TensorFlow.
Fortunately, TensorFlow allows us to learn a new embedding space for every specific task. The process of learning a new embedding space consists of finding the weights of a layer called Embedding in Keras so according to the data and the labels we can create an embedding space that will provide more information about semantic relationships between the words in a document.
To create an embedding layer, you can use the code shown next:
>>>from tensorflow.keras.layers import Embedding
>>>embedding_layer = Embedding(1000,64)
The embedding layer receives at least two parameters, the number of possible tokens (in this example 1000) and the dimension of the embeddings (in the example 64). In other words, the Embedding Layer will receive a 2D tensor of integers, of shape (samples,sequence_length). All sequences must be the same length, otherwise, the sequence will be truncated or padded with zeros.
This layer returns a 3D floating-point tensor of shape (samples, sequence_length, embedding_dimensionality). At the beginning the weights of the embedding layer will be random, just as with any other layer. However, during the training process, these weights are gradually adjusted through back-propagation, structuring the space into something the downstream model can use to make predictions.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Using word embeddings for sentiment analysis.
Let’s apply the concepts explored here to build a model able to classify movie reviews.
Data overview
The dataset that will be used for binary sentiment classification contains more data than other benchmark datasets. Specifically, this dataset provides 25000 positive movie reviews and 25000 negative movie reviews. The dataset can be found on the Kaggle platform using the following link: IMDB dataset. Let’s take a look at how a movie review looks.
'A wonderful little production. The filming technique is very unassuming- very old-time-BBC fashion and gives a comforting, and sometimes discomforting, sense of realism to the entire piece. The actors are extremely well chosen- Michael Sheen not only "has got all the polari" but he has all the voices down pat too! You can truly see the seamless editing guided by the references to Williams' diary entries, not only is it well worth the watching but it is a terrificly written and performed piece. A masterful production about one of the great master's of comedy and his life. The realism really comes home with the little things: the fantasy of the guard which, rather than use the traditional 'dream' techniques remains solid then disappears. It plays on our knowledge and our senses, particularly with the scenes concerning Orton and Halliwell and the sets (particularly of their flat with Halliwell's murals decorating every surface) are terribly well done.'
The text shown above corresponds to a positive review, Python handles these reviews as strings of variable length. Let’s explore the methods that we might use to transform text data into numerical features, this is an important step since most machine learning models use numerical features during the training process. The data frame, which contains the text data, looks like this:
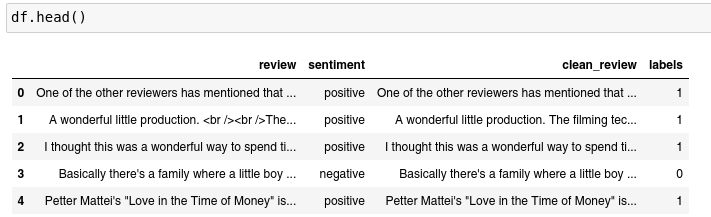
We can see 4 columns, to train the model I will just use the clean_review and labels columns that contain the reviews and the labels for each one, 1 means a positive review while 0 a negative review.
Tokenization
TensorFlow provides a class called Tokenizer,this will obtain the minimum unit of information from the data or “tokens”.
tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~tn',
lower=True, split=' ', char_level=False, oov_token=None,
document_count=0, **kwargs
)
The Tokenizer class receives at least one argument, which refers to the maximum number of words to keep based on word frequency. The class implements a filter to remove punctuation, tabs, and line breaks. Finally, by default, the tokens are at the word level.
The tokenizer creates a dictionary that maps words to index, this dictionary looks like:
>>>tokenizer.word_index
{'the': 1,
'and': 2,
'a': 3,
'of': 4,
'to': 5,
'is': 6,
'in': 7,
'it': 8,
'i': 9,
...
}
After this process we need to convert each document into a sequence, we can do this by using the method texts_to_sequences, later we need to pad each sequence specifying the max length that would have every sequence so the original sequence will be truncated or padded with zeros depending on the specified max length.
Since I defined the max length of the sequence as 100, I got a matrix of shape (50000,100), this is, 50000 reviews with a length of 100. Let’s see how these sequences look. To do this we can use the word index dictionary to map indexes to words.

Splitting the data.
Let’s create the training set to fit the model and a testing set to validate how the model performs. I will use 40000 reviews to train the model and the rest for validation purposes.
Variables like training_samples and validation_samples were defined previously.
Building the model.
I will define a simple model to classify between positive and negative reviews. The model will start with an embedding layer since the output of this layer will be a 3D tensor. This layer needs to be flattened to feed a dense layer, due to this I will use a GlobalAveragePooling1D layer, which averages the vector to flatten the output. After that, the model will be formed by two dense layers. The model architecture is shown below.

To accelerate the learning process, I will use callbacks to implement early stopping, which allows preventing overfitting. In addition, to improve the learning process, it is a good idea to use the ReduceLROnPlateau callback. This implementation will reduce the learning rate when the model performance has stopped.
How to Use Callbacks with TensorFlow and Keras
Model Performance.
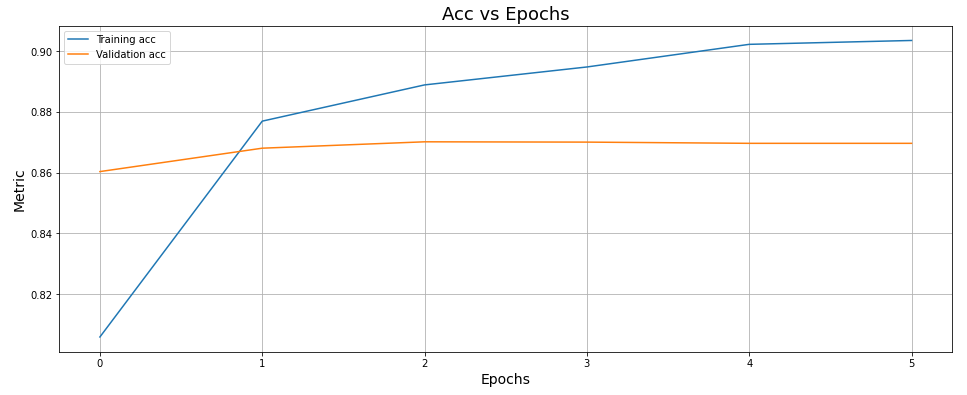
The model tends to overfit since the accuracy over the training data improves faster while the accuracy over the testing data seems to stagnate.
We can see the same behavior on the loss graphic, the loss over the training data decrease suddenly, while the loss over testing data increase so using the early stopping technique helps to get the best model and stop the training process.
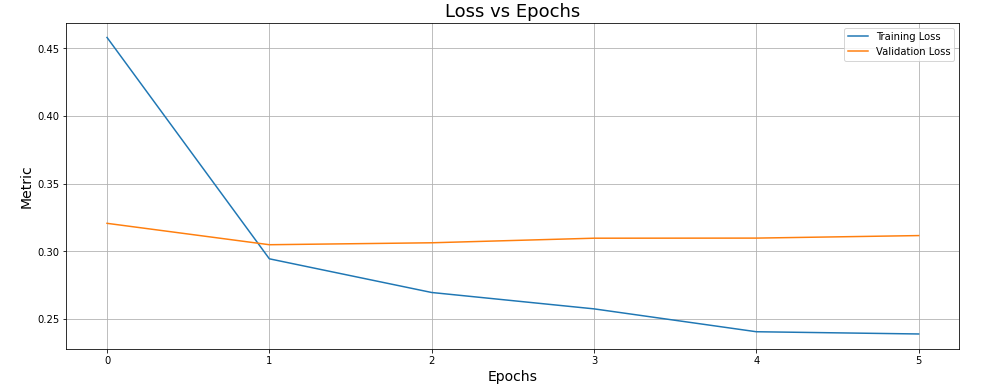
The general accuracy of this model is 86.80 %, this is quite good for a basic implementation of embedding layers, so adjusting parameters to improve the model will help to obtain a better performance.
Visualizing the embedding layer
To visualize the embedding layer we need to extract the weights of the first layer. Using these weights, we can get the vector corresponding to every word in our vocabulary. This way, we can generate a file with the information necessary to generate the visualization via this website
In the animation shown above we can see our embedding space. We can see how this space tends to be grouped into two opposite sides corresponding with the kind of problem we are dealing with. If you want to know more details about the code used to develop this project you can see it in my GitHub repository.
Conclusions.
Sentiment Analysis is a common task in Natural Language Processing. However, it is challenging owing to the complexity of human language. For instance, one movie review can start with compliments about the performance of the actors and finish with bad comments about the movie leading to a negative review. Another scenario is when people use sarcasm to form an opinion. Just imagine, many people don’t even understand sarcasm. So, it is fair enough to think that one machine will struggle to understand these aspects of human language.
We have learned how to use TensorFlow to process text data and build machine learning models to handle problems that have text data as their inputs.
I am passionate about data science and like to explain how these concepts can be used to solve problems in a simple way. If you have any questions or just want to connect, you can find me on Linkedin or email me at manuelgilsitio@gmail.com
References
- TensorFlow for text processing
- Francois Chollet, Deep Learning with Python. New York:Manning Publications Co. 2018
- Akshay Kilkarni and Adarsha Shivananda. Natural Language Processing Recipes. New York: Apress. 2019
- Embedding projector.
Don’t forget to give us your 👏 !




Using Word Embeddings with TensorFlow for Movie Review Text Classification. was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.