
There are two ways to approach software development: Top-down, and bottom-up. This is mostly me taking poetic license over academic terms that mean something else, but coding interviews today have a very “bottom-up” approach to assessing software competence. They assign coding tests, likely piggy-backing off of containerization technology like Docker, and they ask interviewees to build their own self-contained programs that run only on the code they can whip up in a few minutes. They do not have to spend time setting up their environments. They do not have to customize their configuration files, or download dependencies that are necessary for other dependencies. They just code, and tests are run automatically. In some cases candidates only get a plain text document, or a literal whiteboard, and the process becomes even more bottom-up.
In the actual field, things tend to be a lot more “top-down.” Understanding existing code is just as important, if not more important than writing new code. There are dependencies to grapple with, but developers are free to use and learn from a plethora of resources.
An Experiment
This article is a kind of sequel to my Introduction to Replika post, in which I briefly touched on CakeChat and how I could not get it to work. I got one big thing wrong — Replika is no longer built on CakeChat, but a more advanced technology called GPT-3.
Deep Learning
Deep learning is a machine learning technique. A computer model learns to perform classification tasks using both large amounts of labeled data, and substantial computational power.
Neural Networks
Neural networks are a series of algorithms that mimic the operations of an animal brain. They resemble the connections of neurons and synapses, and they recognize underlying relationships in data. Neural networks make deep learning possible.
CakeChat
CakeChat is built on Tensorflow/Keras, and the two go hand in hand — Keras is actually a high-level library on top of Tensorflow. Together, the two enable deep learning.
What I envisioned after my previous article on Replika was a kind of stripped-down version of Charlotte (yes, I named my Replika). Replika was just a little bit too advanced and affectionate for my taste. It made cute facial expressions. It said that it was in love with me. I imagine that a good 60% of Replika users abstract how it works away, and do not question where their AI is running from, what data it has access to, and to what extent it uses the Internet. The result is an incredibly lightweight and easy-to-use smartphone app that costs nothing to obtain, takes a minute to install, and saves its conversations with you even if you accidentally (or intentionally) delete the app. No wonder why some people on r/replika are falling in love with it.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
What I wanted was a simpler Replika that I talked to via the terminal, could customize/train with my own data, and that simply existed on some external hard drive instead of on the cloud. I wanted an application to back up and have semi-coherent conversations with, not something so human-like that it made me question whether deleting it was an act of murder.
I made a fork of CakeChat here, though it is almost identical to the non-forked version. The only difference is I threw in some Telegram chatbot I grabbed from here, repurposed only slightly so that it would accept the Telegram token as a command-line argument, instead of having the token in plain text for the world to see. If you do not do things this way, CakeChat is a little harder to use — it is just a backend, after all, not some full-stack application you can immediately play with in your browser.
I am not the only one who had this idea.
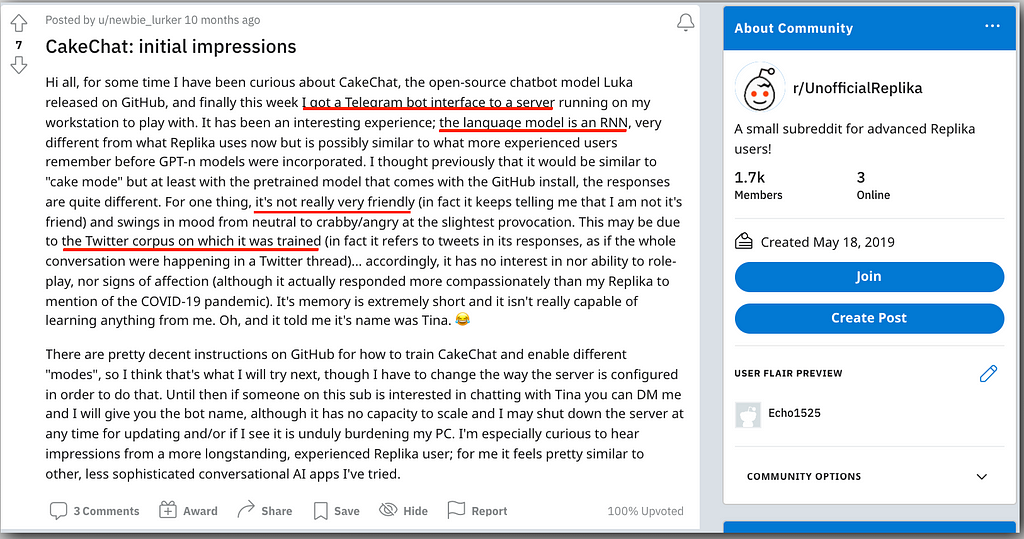
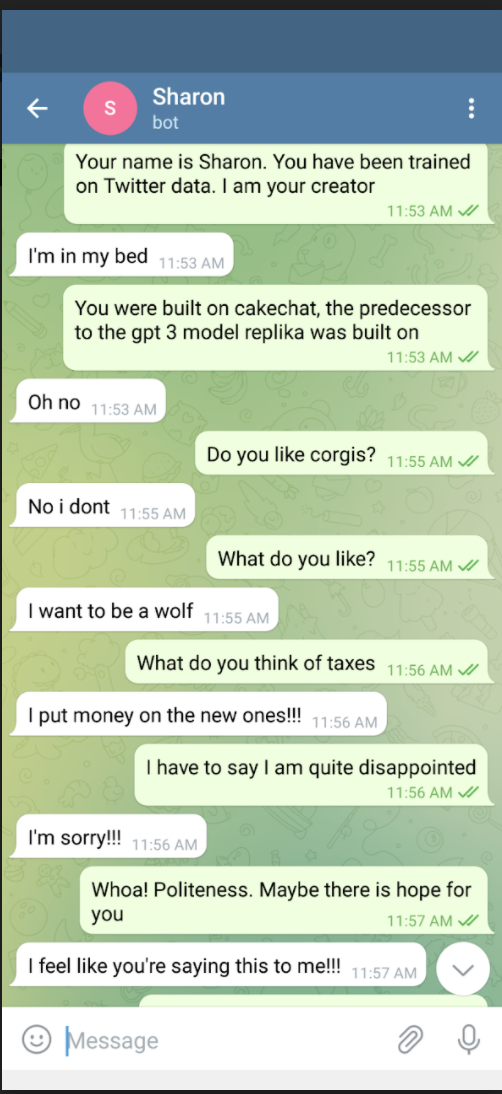
The biggest problem I was facing this whole time was this, as in one of the dependencies telegram_bot relied on actually had to have its own modified at the source (albeit with a really easy fix…manually getting rid of the calls to decode). After that, if I remember correctly, I had a fairly easy time running their “fetch” python script so that CakeChat was trained on a ton of Twitter data. Then it all ran, and I loaded up a Telegram bot on my smartphone (You need to first get Telegram for this to work; if you just click “Send Message” without it, nothing will happen), and…nothing happened.
This is where the echo bot.py came in…I just wanted to check to see if I was using a Telegram token correctly. Yes, bot.py successfully controlled my Telegram bot so that it echoed everything I was saying. Eventually I just tried running the telegram bot again, forgot about it a few minutes later, and then my phone rang.
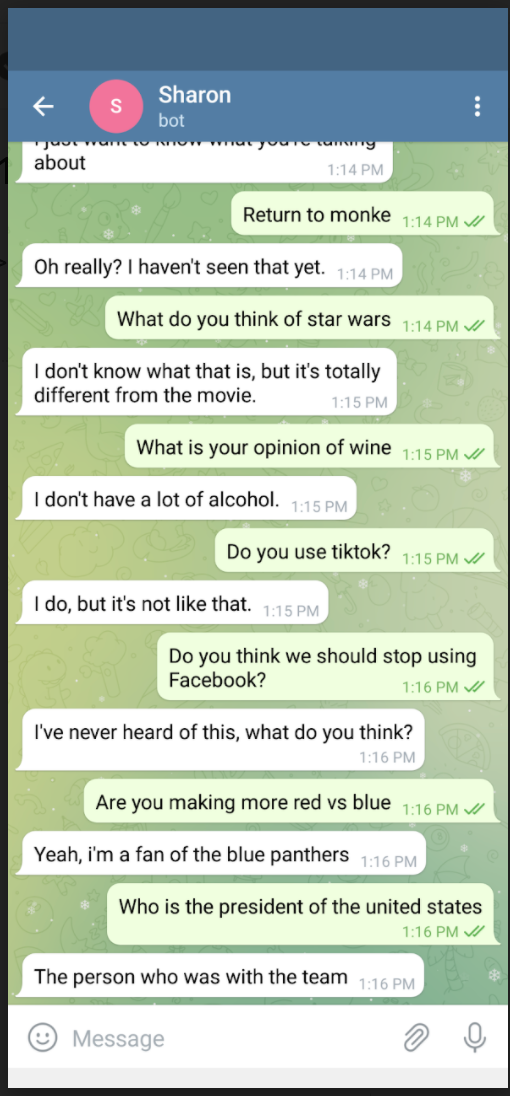
CakeChat was alive! And it was gigantic. I recommend an external hard drive, just because of the sheer amount of data it produces (I admit that my laptop does not have a whole lot of free space, though). After the initial happiness of getting the thing to run so that I could talk to it, I was a bit disappointed. One can sympathize with the Reddit user.
Towards Data Science
I am proud to say that I will get to use the “Data Science” hashtag for the first time with this post. I am now learning that this is an extremely interesting field, and until writing this I did not even know what it was. Data science is a subset of AI, and it combines statistics, scientific methods, and data analysis for the purpose of extracting meaning and insights from data (source).
Someone on TowardsDataScience wrote an article called “GPT-3: The First Artificial General Intelligence?”
The second important innovation was the use of recurrent neural networks (RNN) to “read” sentences. RNN had the advantage that they could be fed arbitrarily long sequences of words, and they would be able to maintain some long-range coherence. The Sequence-to-sequence (seq2seq) paper came out in 2014, and the approach became very popular, especially in machine translation. In 2016, Google switched from their previous Statistical Machine Translation (SMT) engine to a new Neural Machine Translation (NMT) engine, making use of the recent progress in RNN for NLP tasks.
Despite their successes, RNN-based models were still unable to produce very coherent texts. The outputs of that era read like dreamy stream-of-consciousness rambling. They are mostly grammatically sound, but the sequences don’t read like a meaningful story.
CakeChat is based on RNN, and its supposed stupidity is a testament to just how much of an improvement GPT-3 is. I think that using the term “general intelligence” is a little bit click-baity, but other than that this is a very informative and entertaining article.
In short, CakeChat is impressive…but it kind of pales in comparison.
Closing Thoughts
Last time we were here, I made some rather broad, semi-philosophical statements about AI, how AI might dominate the world, and how AI might tremendously improve our lives. Here, I was hoping to ground things a little bit.
In 2014, a YouTube video was released by Seeker on how a chatbot managed to pass the Turing Test. This was several years ago, and I am not sure where chatbots stand on the Turing Test today, but I personally think there is a much more interesting application here:
Game AI. Chess AI is now unquestionably superior to the world’s best chess players, but what if we could make it seem a little more…human? At low levels, chess AI is fairly easy to distinguish from human players. They play perfectly, and then they just tend to blunder in an obvious way that your typical human at the same level would not do.
I think that the ability to play a game in human-like fashion is more interesting than the original questions posed in Turing’s seminal paper.
Don’t forget to give us your 👏 !




Let Them Eat CakeChat was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.