
Artificial Intelligence is rapidly getting into the workflow of many businesses across various industries. Due to the advancements in Natural Language Processing (NLP), Natural Language Understanding (NLU), and Deep Learning (DL), we are now able to develop technologies capable of imitating human-like interactions which include recognizing speech, as well as text.
In this article, we are going to build a Conversational Chatbot app using Transformer (microsoft/DialoGPT-medium model), streamlit.
Transformer Model
A State-of-the-Art Large-scale Pretrained Response generation model (DialoGPT)
DialoGPT is a SOTA large-scale pretrained dialogue response generation model for multiturn conversations. The human evaluation results indicate that the response generated from DialoGPT is comparable to human response quality under a single-turn conversation Turing test. The model is trained on 147M multi-turn dialogue from Reddit discussion thread.
Streamlit
Streamlit is an open-source Python library
Streamlit makes it easy to create and share beautiful, custom web apps for machine learning and data science. In just a few minutes we can build and deploy powerful data apps.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Installation of Packages
Transformers: This library brings together over 40 state-of-the-art pre-trained NLP models (BERT, GPT-2, Roberta, etc..)
Torch: Python-based scientific computing package
Streamlit: To create a custom web app.
# Install Transformers
!pip install transformers
!pip install torch
!pip install streamlit
Import Libraries
Importing the libraries that are required to perform operations on the dataset.
import streamlit as st
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
Load the tokenizer and model
Streamlit cache, caches the tokenizer and the model. This avoids reloading of the tokenizer and the model and thus improving the performance.
@st.cache(hash_funcs={transformers.models.gpt2.tokenization_gpt2_fast.GPT2TokenizerFast: hash}, suppress_st_warning=True)
def load_data():
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")
return tokenizer, model
tokenizer, model = load_data()
Set up the streamlit
In the session state of streamlit, we are storing the below items:
chat_history_ids: Stores the conversations made by the user in that session.
count: Count of conversations. It was observed that the model was not giving good results after 5 sequential conversations. So we use this counter to clear the chat history.
old_response: Stores the previous response by the model. Sometimes the model generates the same response as the previous, using this variable we can track such duplicate responses and we can regenerate the model response.
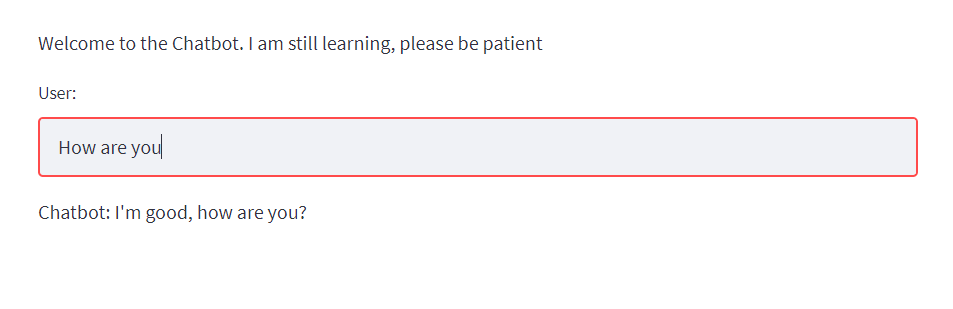
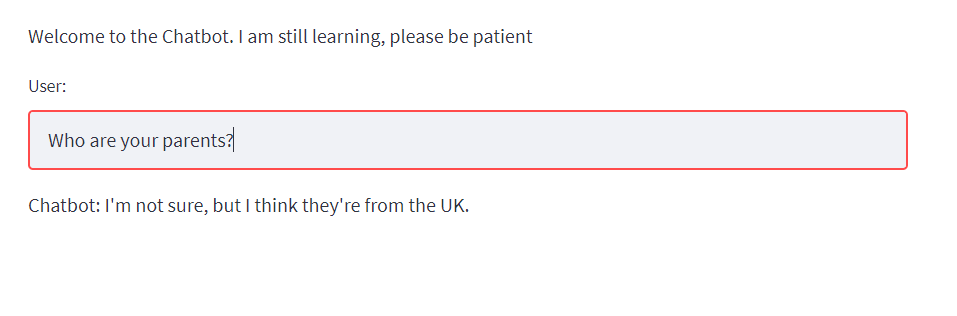
st.write("Welcome to the Chatbot. I am still learning, please be patient")
input = st.text_input('User:')
if 'count' not in st.session_state or st.session_state.count == 6:
st.session_state.count = 0
st.session_state.chat_history_ids = None
st.session_state.old_response = ''
else:
st.session_state.count += 1
Tokenizing the user input and returning the tensor output
new_user_input_ids = tokenizer.encode(input + tokenizer.eos_token, return_tensors=’pt’)
Appending the user input ids to the chat history ids
bot_input_ids = torch.cat([st.session_state.chat_history_ids, new_user_input_ids], dim=-1) if st.session_state.count > 1 else new_user_input_ids
Generating a response while limiting the total chat history to 5000 tokens
st.session_state.chat_history_ids = model.generate(bot_input_ids, max_length=5000, pad_token_id=tokenizer.eos_token_id)
Decoding the response
response = tokenizer.decode(st.session_state.chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)
Regenerating the response if the old response from the model is the same as the current response.
if st.session_state.old_response == response:
bot_input_ids = new_user_input_ids
st.session_state.chat_history_ids = model.generate(bot_input_ids, max_length=5000, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(st.session_state.chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)
Displaying the response on the UI
st.write(f”Chatbot: {response}”)
Updating the old_response variable
st.session_state.old_response = response
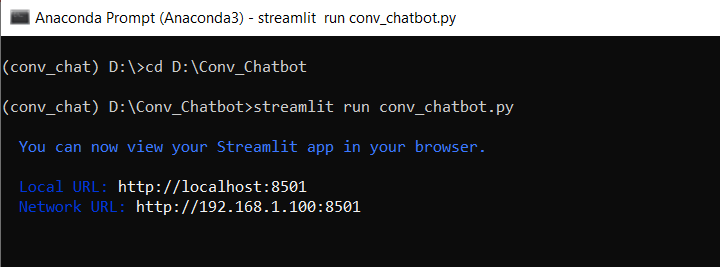
The app can be easily run in the local environment
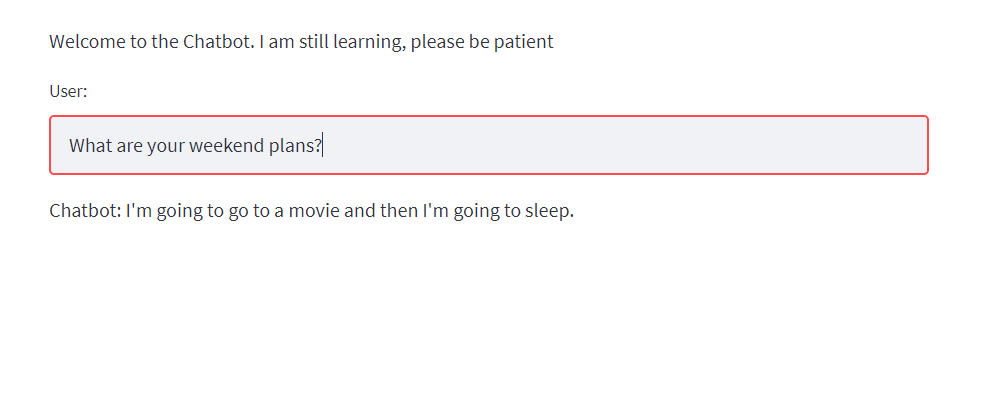
The conversational chatbot is up and running
Don’t forget to give us your 👏 !




Conversational Chatbot using Transformers and Streamlit was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.