A custom python model which automatically clean up the utterances and generate the possible clusters and slots, making it easier for you in merging those clusters together to form as many intents as you need to feed a chatbot?
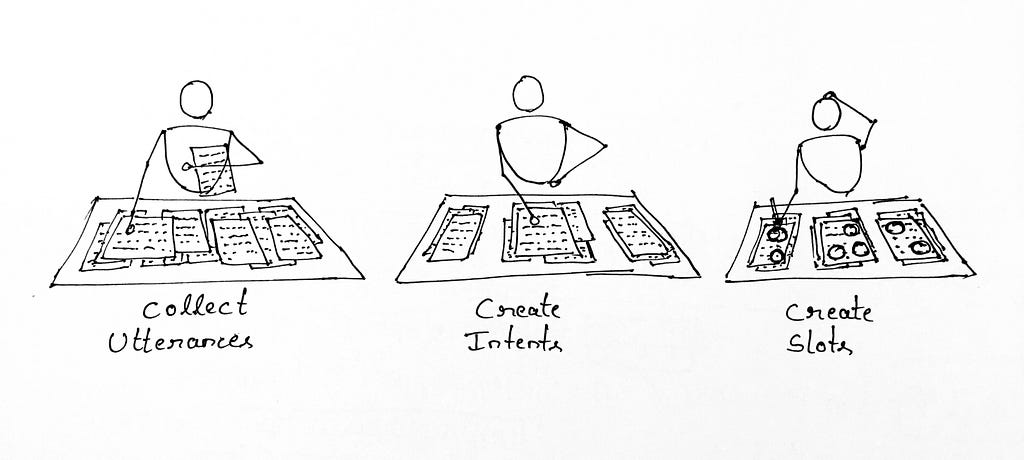
To build a chatbot, I feel that the high-level steps we usually take are the following.
- Collect Utterances and Cleanup — This includes removing unwanted utterances, email ids, numeric and special characters
- Create Intents — Analyse the utterances and start clustering the related utterances together to form intents.
- Create Slots — Identify associated words in the utterances to form slots/entities.
- Select NLP — The core component that interprets the user’s utterance and converts that language to structured inputs (Intents and Slots) the system can process. The top NLPs available in the market such as AWS Lex, Microsoft LUIS or Google Dialog Flow, etc…
- Build — Train the chatbot with utterances and attach slots
- Publish — Publish to get an endpoint of the chatbot
- Write Response Logic — Write backend logic in any programming language of your interest, to respond to the user’s utterance.
The most important role among the above 7 steps is played by your NLP, being intelligent enough to understand what the context of a user is. So, it is imperative to capture a variety of example utterances and accurately classify them into intents to provide better accuracy in predicting the new utterances. That means you have to spend more time analyzing the utterances, removing duplicates, special characters, and misrepresentations, before classifying them.
How complicated is it to create Intents and Slots?
Let’s take some examples of booking related utterances,
Is my booking confirmed?
I need to book a flight from Bangalore to Paris
Can I get the top 5 hotels list for accommodation?
I have not got any confirmation of my booking
Which is the best locality to stay in Paris?
How can I book a ticket to Paris?
I have to travel to Amsterdam tomorrow
Which is the closest hotel to Paris airport?
Stop here for a while without scrolling below and think how many intents and slots can be created? (Note how much time it took for this activity to complete)
The “context” of each utterance must be carefully understood and separated based on how similar or dissimilar one is to others.
Here’s how I feel they can be classified at a high level-
Trending Bot Articles:
3. Concierge Bot: Handle Multiple Chatbots from One Chat Screen
I need to book a flight from Bangalore to Paris
How can I book a ticket tonight to Paris?
I have to travel to Amsterdam tomorrow
Can I get the top 5 hotels list for accommodation?
Which is the best locality to stay in Paris?
Which is the closest hotel to Paris airport?
Is my booking confirmed?
I have not got any confirmation of my booking?
> The first cluster is talking about booking a flight for a location
> Second cluster talks about hotels inquiry and
> The third cluster collecting the common utterances which can be related to any bookings.
W.R.T slots,
> SourceLocation- Bangalore
> DestinationLocation- Paris/Amsterdam
> Day- tonight, tomorrow
So, there can be 3 intents and 3 slots. It looks easy right!
Now, what if we have 10,000 raw utterances? How long do you think you need to generate slots and intents?
It just isn’t finishing here. Most of the time, the utterances that you get would not be that clean. As I said before feeding them to your NLP you need to remove unwanted stuff from the data sets.
Even if you have a good amount of experience in building chatbots, you have to spend more time preprocessing the utterances. I can say it would take weeks for an experienced and months for an average or naive.
So, what do we do?
What if there is a program that can reduce your effort in doing this?
Reduce your effort of these 3 below
- Collect Utterances and Cleanup
- Create Intents
- Create Slots
Let me think! Basically, we need something which automatically cleanup, compares one sentence with another to group sentences that are more similar (greater than 80%) to each other, and identifies slots.
In more technical terms,
- First, sentences to be preprocessed
- then, convert sentences to vectors (Embedding) and compare vectors and group the similar ones
- later, identify the most frequently occurring words contextually in the entire corpus
I spent a lot of time with trial and error seeing if there’s something that can help me cluster the utterances without asking me how many clusters are needed. Because I don’t have any idea how many clusters or intents do I need.
I found a few models that were doing the job but, due to lack of data, there was a lot of mix and match. They work really well on a huge amount of like millions of utterances. But, my dataset is not that huge and the scope is limited. So, I finally thought let’s write a custom model that can fit my requirements.
How is the custom model implemented?
This custom model is inscribed in python.
- First, we need to preprocess the data
Lowercase, Remove email ids and URLs, Remove special characters and numbers, Remove stopwords, and finally Lemmatize (Identify and replace the base form of a word) if you are interested.
2a. Convert sentences to vectors
This and the preprocessing are the most crucial steps in the entire ML automation process. I assume here that you know, why we convert sentences to vectors. There are many ways to do this and I would choose a few of them such as TFIDF, Word2Vec, and BERT. You can go through a few tutorials and articles to find out how do they work.
2b. Grouping the similar sentences
Here you need a logic that compares the sentences and group (actually compare the vectors).
There are two most popular formulas used to find the distance between two vectors
a. Cosine Similarity
b. Euclidean Distance
3. Contextually occurring similar words
We will use our basic logic to figure out how words appear between their neighbouring words and how frequently they appear with the same neighours.
Let’s run the code
It takes an excel file that contains the list of utterances as input and returns another excel file containing the most possible slots and clusters.
To begin, clone the master branch or download it from the GitHub location.
“https://github.com/machinelearning01/text-clustering”
Go to the test1.py file and pass the excel file path in the parameters.
"excel_data": input_data("<excel file path>"),
Run the code and see the results in excel ready!
$ python test1.py
Conclusion
For a single problem, there’ll always be different ways. This custom model saves weeks of time from looking again and again at the same utterances that it is not sure where the chatbot accuracy ends up. So, I suggest you look at the model and run through it to see the result variations you’re getting, train, and test the chatbot and let me know your comments.
Don’t forget to give us your 👏 !




Automatic Utterances Clustering for Chatbots was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.