In November 2020, Amazon Alexa added more new speech presets (“musical” and “conversational”) to their “Excited/Disappointed” Speech Synthesis Markup Language (SSML) presets debuted in November 2019.* Although Alexa does provide examples of the code for each preset, they are still pretty vague (good internal coding) so from an audio/neuroscience view, I was interested in what made the voices sonically different and how that compared to current literature on acoustic characteristics of language and emotional prosody, using the examples from their website.
*I am a student and not affiliated with Amazon. All sounds, code and news are publicly available.
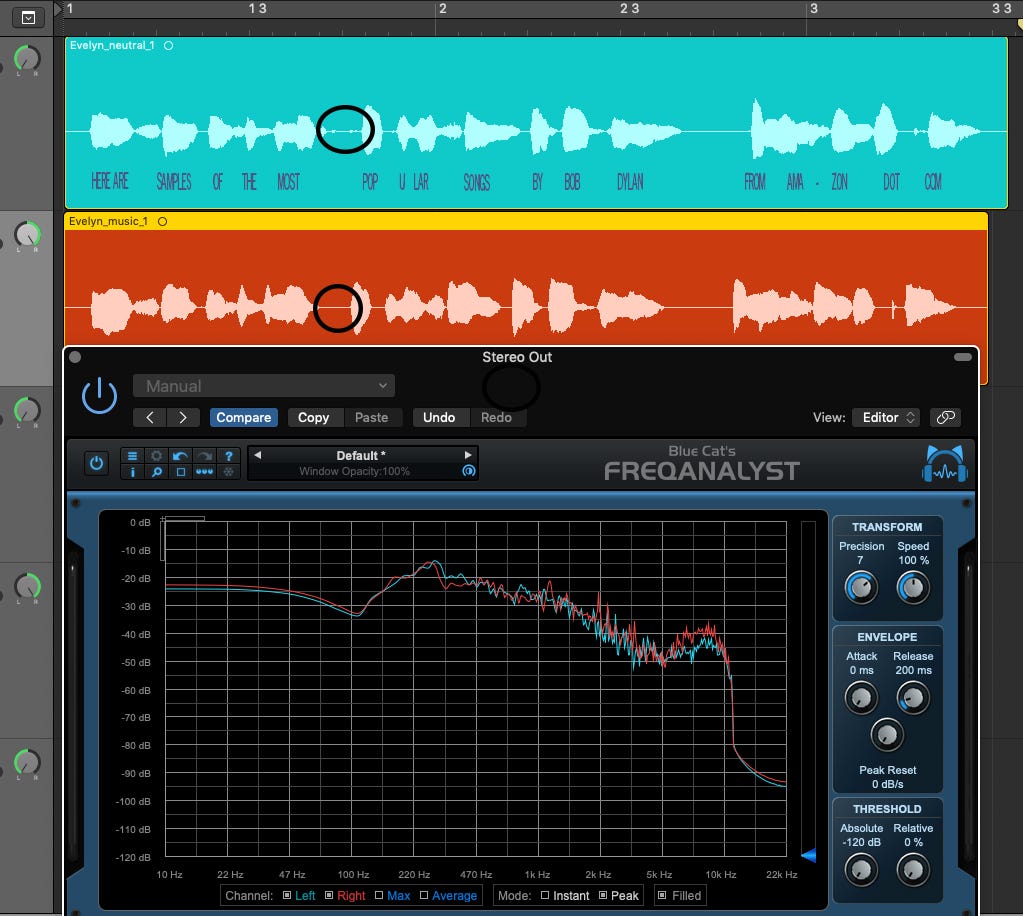
With the original and new audio examples hard-panned L and R respectively, I was able to use Blue Cat Audio’s Freqanalyst Logic Pro X Plug-in to have a side-by-side peak frequency comparison. I would’ve loved to use a spectrogram for more accurate frequency/time comparison but A. Logic doesn’t have a good one to my knowledge and B. they are harder to visually compare side-by-side. (Any suggestions on how I could improve my testing methods though are graciously taken — I think Reaper has one that I’m not familiar with?). I also compared the temporal aspect of the voices’ pauses through visual comparison of the wave forms. In every example shown below, the original voice is always represented by the color blue and the new preset is in red. Since each example uses the same words as its counterpart, there should be no frequency difference due to phoneme differences. The audio files were also the same gain/volume.

The “musical” speech (below) changes intonation and time–the voice is faster to reach the syntactic emphasis of the sentence (SomeOfTheMost POPULAR). The musical voice is also louder in the upper frequencies. Amazon suggests this mode to “emulate DJs or radio hosts”/ “Style the speech for talking about music, video, or other multi-media content”. This, however, isn’t a definable auditory preset so there’s no specific comparison to be made to current literature in the same way as emotional language; the use of “musical” in this context has brought up debate on their nomenclature among some sound researchers.
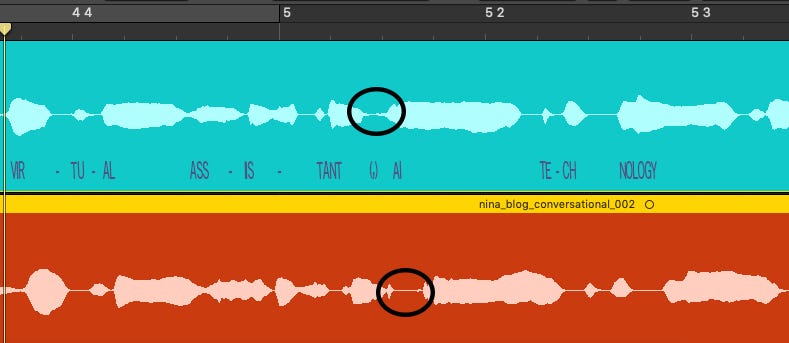
The “conversational” style (below) is slower in total than the neutral original, adding commas where human speech would likely take a breath for clarity. See the added pause between “virtual assistant” and “AI technology”. I don’t know if this pause was added via code or AI; based on the technical details provided by Amazon it doesn’t look like pauses are added in manually, however I know that there are SSML options to create pauses based on specific time duration or based on “strength” (syntactic emphasis e.g. paragraph vs. sentence breaks and commas). Potentially related, the pause in the new (red) speech is completely silent, as if there’s a noise gate on the signal, as compared to the blue original which shows tails of the voice. Using a gate or some other forced clipping could be a way of emphasizing the pause without changing the actual timing as much.
Trending Bot Articles:
1. The Messenger Rules for European Facebook Pages Are Changing. Here’s What You Need to Know
3. Facebook acquires Kustomer: an end for chatbots businesses?
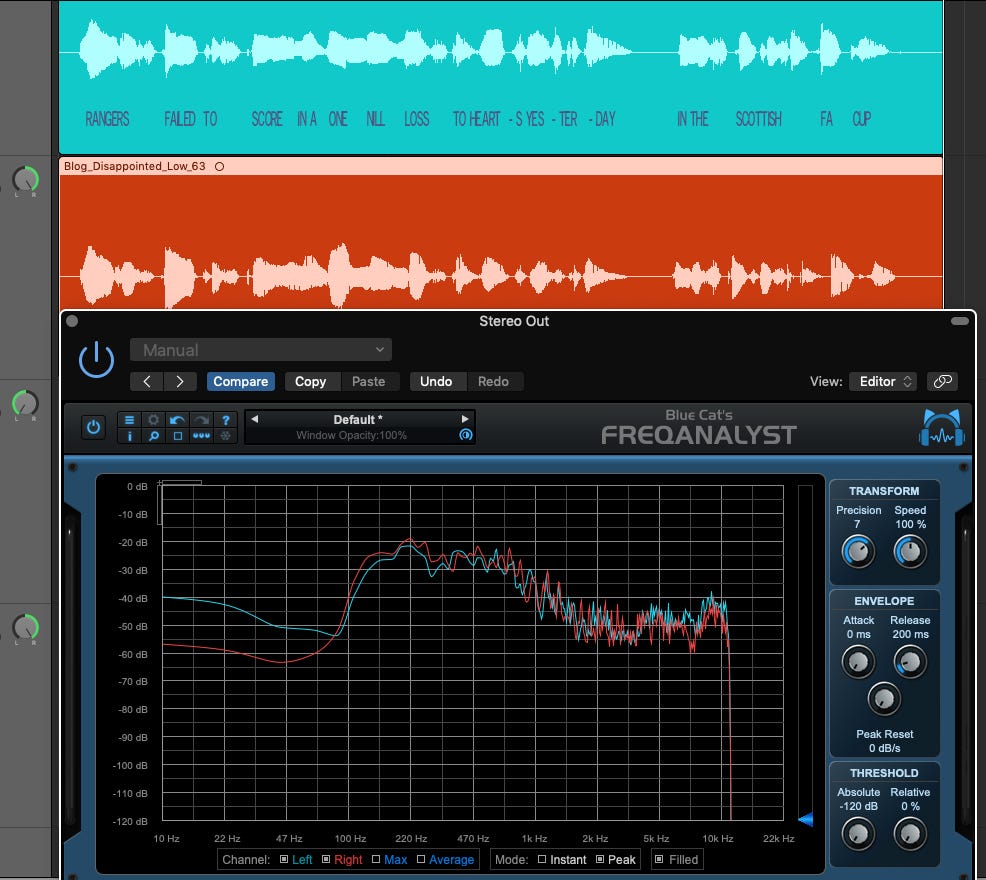
The “disappointed” speech is (uniquely) temporally identical to neutral, however the new speech is lower in the upper frequencies. Neither of these differences match standard emotional prosody from what I know. The sad voice does appear to have a lower 1st formant though (Juslin/Laukka, 2001)
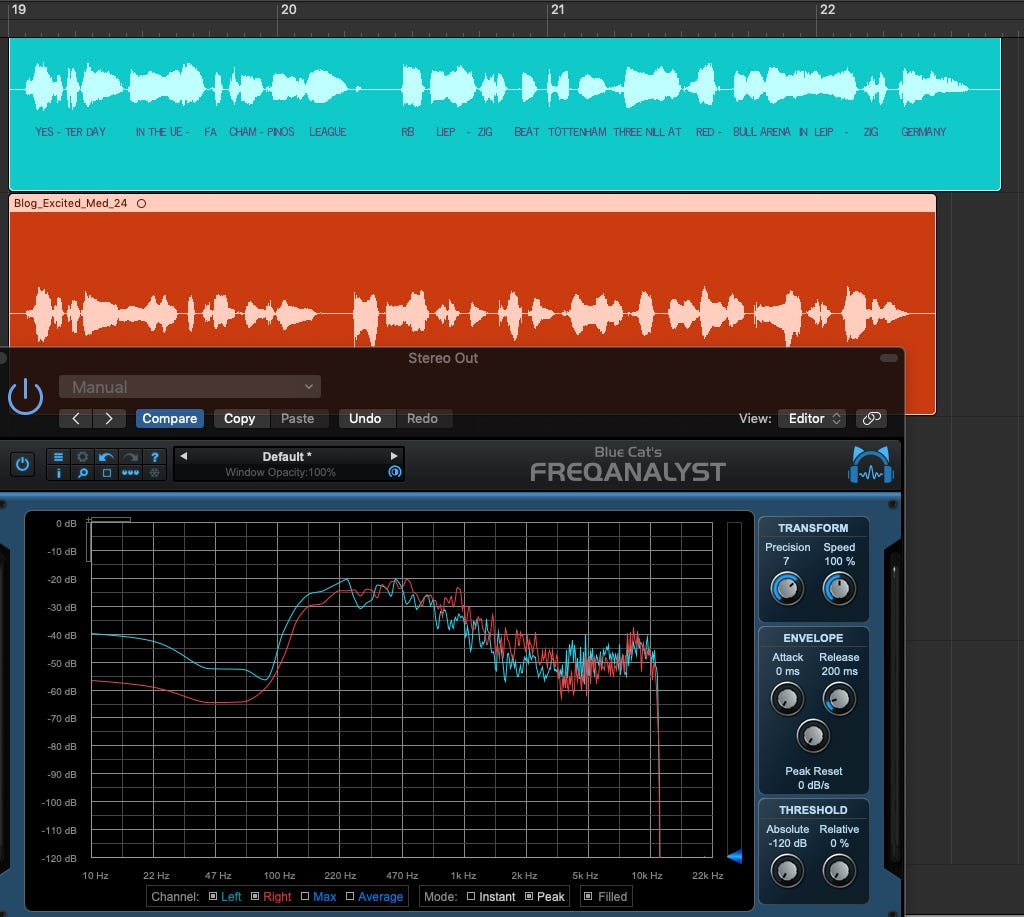
The “excited” speech is considerably faster than the original and had some of the most frequency variation from the neutral speech. Using Juslin/Laukka again, you can see the first formant is lower in the original in comparison to the excited speech, which follows their findings in emotional prosody/acoustic characteristics of emotional speech.
Don’t forget to give us your 👏 !




Happy Alexa, Sad Alexa… was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.