Introduction
The article explores the practical application of essential Python libraries like TextBlob, symspell, pyspellchecker and Flan-T5 based grammar checker in the context of spell and grammar checking. It provides a detailed overview of each library’s unique contributions and explains how they can be combined to create a functional system that can detect and correct linguistic errors in text data. Additionally, the article discusses the real-world implications of these tools across diverse fields, including academic writing, content creation, and software development. This valuable resource is intended to assist Python developers, language technologists, and individuals seeking to enhance the quality of their written communication.
Learning Objectives:
In this article, we will understand the following:
- What are the spell checker and grammar checker?
- Different Python libraries for spell checker and grammar checker.
- Key takeaway and limitation of both approaches

Overview
In today’s fast-paced digital landscape, the need for clear and accurate written communication has never been more crucial. Whether engaging in informal chats or crafting professional documents, conveying our thoughts effectively relies on the precision of our language. While traditional spell and grammar checkers have been valuable tools for catching errors, they often need more regarding contextual understanding and adaptability. This limitation has paved the way for more advanced solutions that harness the power of Natural Language Processing (NLP). In this blog post, we will explore the development of a state-of-the-art spell and grammar checker utilising NLP techniques, highlighting its ability to surpass conventional rule-based systems and deliver a more seamless user experience in the digital age of communication.
The ever-growing prominence of digital communication has placed immense importance on the clarity and accuracy of written text. From casual online conversations to professional correspondence, our ability to express ourselves effectively is deeply connected to the precision of our language. Traditional spell and grammar checkers have long been valuable tools in identifying and correcting errors, but their contextual understanding and adaptability limitations have yet to be desired. This has spurred the development of more advanced solutions powered by Natural Language Processing (NLP) that offer a more comprehensive approach to language-related tasks.
Natural Language Processing (NLP) is an interdisciplinary field that combines the expertise of linguistics, computer science, and artificial intelligence to enable computers to process and comprehend human language. By harnessing the power of NLP techniques, our spell and grammar checker seeks to provide users with a more accurate and context-aware error detection and correction experience. NLP-based checkers identify spelling and grammatical errors and analyse context, syntax, and semantics to understand the intended message better and deliver more precise corrections and suggestions.
This post will delve into the core components and algorithms that drive our NLP-based spell checker. Furthermore, we will examine how advanced techniques like Levenshtein distance and n-grams contribute to the system’s ability to identify and correct errors. Finally, we will discuss advanced LLM-based contextual spell and grammar checkers. Join us on this exciting journey to uncover how NLP revolutionises how we write and communicate digitally.
Spell Checker
Python-based spell checkers employ various techniques to identify and correct misspelled words. Here’s a deeper dive into the technical details:
- Word Frequency Lists: Most spell checkers use word frequency lists, which are lists of words with their respective frequencies in a language. These frequencies suggest the most probable correct spelling of a misspelled word. For instance, the ‘pyspellchecker’ library includes English, Spanish, German, French, and Portuguese word frequency lists.
- Edit Distance Algorithm: This method determines how similar two strings are. The most commonly used is the Levenshtein Distance, which calculates the minimum number of single-character edits (insertions, deletions, substitutions) required to change one word into another. ‘pyspellchecker’ uses the Levenshtein Distance to find close matches to misspelt words.
- Contextual Spell Checking: Advanced spell checkers, like the one implemented in the ‘TextBlob’ library, can also perform contextual spell checking. This means they consider the word’s context in a sentence to suggest corrections. For instance, the misspelt word “I hav a apple” can be corrected to “I have an apple” because ‘have’ is more suitable than ‘hav’ and ‘an’ is more suitable before ‘apple’ than ‘a’.
- Custom Dictionaries: Spell checkers also allow the addition of custom dictionaries. This is useful for applications that deal with a specific domain that includes technical or specialized words not found in general language dictionaries.
Python’s readability and the powerful features offered by its spell-checking libraries make it a popular choice for developers working on applications that require text processing and correction.

1. PySpellChecker
A pure Python spell-checking library that uses a Levenshtein Distance algorithm to find the closest words to a given misspelled word. The Levenshtein Distance algorithm is employed to identify word permutations within an edit distance of 2 from the original word. Subsequently, a comparison is made between all the permutations (including insertions, deletions, replacements, and transpositions) and the words listed in a word frequency database. The likelihood of correctness is determined based on the frequency of occurrence in the list.
pyspellchecker supports various languages, such as English, Spanish, German, French, Portuguese, Arabic, and Basque. Let us walk through with an example.
- Install the packages
!pip install pyspellchecker
2. Check for miss spell words
from spellchecker import SpellChecker
spell = SpellChecker()
misspelled = spell.unknown(['taking', 'apropriate', 'dumy', 'here'])
for word in misspelled:
print(f"Word '{word}' : Top match: '{spell.correction(word)}' ;
Possible candidate '{spell.candidates(word)}'")
#output
Word 'apropriate' : Top match: 'appropriate' ; Possible candidate '{'appropriate'}'
Word 'dumy' : Top match: 'duty' ;
Possible candidate '{'dummy', 'duty', 'dumb', 'duly', 'dump', 'dumpy'}'
3. Set the Levenshtein Distance.
from spellchecker import SpellChecker
spell = SpellChecker(distance=1)
spell.distance = 2 #alternate way to set the distance
2. TextBlob
TextBlob is a powerful library designed for Python, specifically created to facilitate the processing of textual data. With its user-friendly and straightforward interface, TextBlob simplifies the implementation of various essential tasks related to natural language processing (NLP). These tasks encompass a wide range of functionalities, including but not limited to part-of-speech tagging, extracting noun phrases, performing sentiment analysis, classification, translation, and more. By offering a cohesive and intuitive API, TextBlob empowers developers and researchers to efficiently explore and manipulate text-based data, enabling them to delve into the intricacies of language analysis and harness the potential of NLP for their applications.
TextBlob is a versatile Python library that offers a comprehensive suite of features for processing textual data. It encompasses a wide range of tasks, including noun phrase extraction, part-of-speech tagging, sentiment analysis, and classification using algorithms like Naive Bayes and Decision Tree. Additionally, it provides functionalities such as tokenization for splitting text into words and sentences, calculating word and phrase frequencies, parsing, handling n-grams, word inflection for pluralization and singularization, lemmatization, spelling correction, and seamless integration with WordNet. Moreover, TextBlob allows for easy extensibility, enabling users to incorporate new models or languages through extensions, thereby enhancing its capabilities even further.
Let us walk through with example.
1. Install the TextBlob package
!pip install -U textblob
!python -m textblob.download_corpora
2. Check the miss spell words in paragraph and correct it.
from textblob import TextBlob
b = TextBlob("I feel very energatik.")
print(b.correct())
3. Word objects have a Word.spellcheck() method that returns a list of (word,confidence) tuples with spelling suggestions.
from textblob import Word
w = Word('energatik')
print(w.spellcheck())
# [('energetic', 1.0)]
The technique used for spelling correction is derived from Peter Norvig’s “How to Write a Spelling Corrector” [1], which has been implemented in the pattern library. The accuracy of this approach is approximately 70%.
Pyspellchecker and TextBlob could be used for misspell word identification and correction.
3. Symspellpy
SymSpellPy is a Python implementation of the SymSpell spelling correction algorithm. It’s designed for high-performance typo correction and fuzzy string matching, capable of correcting words or phrases with a speed of over 1 million words per second, depending on the system’s performance. The SymSpell algorithm works by precomputing all possible variants for a given dictionary within a specified edit distance and storing them in a lookup table, allowing for quick search and correction. This makes symspellpy suitable for use in various natural languages processing tasks, such as spell checking, autocomplete suggestions, and keyword searches.
The dictionary files come with symspellpy and can be accessed using pkg_resources import. Let us walk through with an example.
1. Install the package
!pip install symspellpy
2. symspell for miss-spell word identification
“frequency_dictionary_en_82_765.txt” ships with pip install.
import pkg_resources
from symspellpy import SymSpell, Verbosity
sym_spell = SymSpell(max_dictionary_edit_distance=2, prefix_length=7)
dictionary_path = pkg_resources.resource_filename(
"symspellpy", "frequency_dictionary_en_82_765.txt"
)
sym_spell.load_dictionary(dictionary_path, term_index=0, count_index=1)
input_term = "Managment" #@param
# (max_edit_distance_lookup <= max_dictionary_edit_distance)
suggestions = sym_spell.lookup(input_term, Verbosity.CLOSEST,
max_edit_distance=2, transfer_casing=True)
for suggestion in suggestions:
print(suggestion)
3. To get the original word if no matching word found
sym_spell = SymSpell(max_dictionary_edit_distance=2, prefix_length=7)
dictionary_path = pkg_resources.resource_filename(
"symspellpy", "frequency_dictionary_en_82_765.txt"
)
sym_spell.load_dictionary(dictionary_path, term_index=0, count_index=1)
input_term = "miss-managment" #@param
suggestions = sym_spell.lookup(
input_term, Verbosity.CLOSEST, max_edit_distance=2,
include_unknown=True,transfer_casing=True
)
for suggestion in suggestions:
print(suggestion)
4. spell correction on entire text
import pkg_resources
from symspellpy import SymSpell
sym_spell = SymSpell(max_dictionary_edit_distance=2, prefix_length=7)
dictionary_path = pkg_resources.resource_filename(
"symspellpy", "frequency_dictionary_en_82_765.txt"
)
bigram_path = pkg_resources.resource_filename(
"symspellpy", "frequency_bigramdictionary_en_243_342.txt"
)
# load both the distribution
sym_spell.load_dictionary(dictionary_path, term_index=0, count_index=1)
sym_spell.load_bigram_dictionary(bigram_path, term_index=0, count_index=2)
# lookup suggestions for multi-word input strings
params = "I m mastring the spll checker for reserch pupose." #@param
input_term = (
params
)
suggestions = sym_spell.lookup_compound(
input_term, max_edit_distance=2, transfer_casing=True,
)
# display suggestion term, edit distance, and term frequency
for suggestion in suggestions:
print(suggestion)
Parameter list:
Following parameters can be tuned for optimization
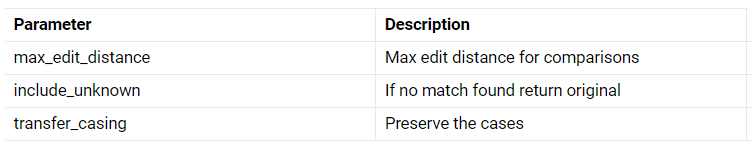
Grammar Checker
1. Flan-T5 Based
The Flan-T5 model, which serves as the foundation for our approach, has undergone meticulous fine-tuning using the JFLEG (JHU FLuency-Extended GUG corpus) dataset. This particular dataset is specifically designed to emphasize the correction of grammatical errors. During the fine-tuning process, great care was taken to ensure that the model’s output aligns with the natural fluency of native speakers.
It is worth noting that the dataset is readily accessible as a Hugging Face dataset, facilitating ease of use and further exploration.
{
'sentence': "They are moved by solar energy ."
'corrections': [
"They are moving by solar energy .",
"They are moved by solar energy .",
"They are moved by solar energy .",
"They are propelled by solar energy ."
]
}
sentence: original sentence
corrections: human corrected version
Dataset description
- This dataset contains 1511 examples and comprises a dev and test split.
- There are 754 and 747 source sentences for dev and test, respectively.
- Each sentence has four corresponding corrected versions.
To illustrate this process, we will utilize a specific example. Here, the input text subdivided into individual sentences. Subsequently, each of these sentences will be subjected to a two-step procedure.
- It will use a grammar detection pipeline to identify grammatical inconsistencies or errors.
- The sentences will be refined via a grammar correction pipeline to rectify the previously detected mistakes. This two-fold process ensures the accuracy and grammatical correctness of the text.
Please make sure you have GPU enabled for faster responses
1.Install the packages
!pip install -U -q transformers accelerate
2. Define the Sentence splitter function
#@title define functions
params = {
'max_length':1024,
'repetition_penalty':1.05,
'num_beams':4
}
def split_text(text: str) -> list:
# Split the text into sentences using regex
sentences = re.split(r"(?<=[^A-Z].[.?]) +(?=[A-Z])", text)
sentence_batches = []
temp_batch = []
for sentence in sentences:
temp_batch.append(sentence)
"""If the length of the temporary batch is between 2
and 3 sentences, or if it is the last batch, add
it to the list of sentence batches """
if len(temp_batch) >= 2 and len(temp_batch) <= 3 or sentence == sentences[-1]:
sentence_batches.append(temp_batch)
temp_batch = []
return sentence_batches
3. Define the grammar checker and corrector function
def correct_text(text: str, checker, corrector, separator: str = " ") -> str:
sentence_batches = split_text(text)
corrected_text = []
for batch in tqdm(
sentence_batches, total=len(sentence_batches), desc="correcting text.."
):
raw_text = " ".join(batch)
results = checker(raw_text)
if results[0]["label"] != "LABEL_1" or (
results[0]["label"] == "LABEL_1" and results[0]["score"] < 0.9
):
# Correct the text using the text-generation pipeline
corrected_batch = corrector(raw_text, **params)
corrected_text.append(corrected_batch[0]["generated_text"])
print("-----------------------------")
else:
corrected_text.append(raw_text)
corrected_text = separator.join(corrected_text)
return corrected_text
4. Initialize the text-classification and text-generation pipeline
# Initialize the text-classification pipeline
from transformers import pipeline
checker = pipeline("text-classification", "textattack/roberta-base-CoLA")
# Initialize the text-generation pipeline
from transformers import pipeline
corrector = pipeline(
"text2text-generation",
"pszemraj/flan-t5-large-grammar-synthesis",
device=0
)
5. Process the input paragraph.
raw_text = "my helth is not well, I hv to tak 2 day leave."
# pp.pprint(raw_text)
corrected_text = correct_text(raw_text, checker, corrector)
pp.pprint(corrected_text)
# output:
#'my health is not well, I have to take 2 days leave.'
Key Takeaway
- ‘Pyspellchecker’ effectively identifies misspelled words but may mistakenly flag person names and locations as misspelt words.
- TextBlob is proficient in correcting misspelt words, but there are instances where it autocorrects person and location names.
- Symspell demonstrates high speed during inference and performs well in correcting multiple words simultaneously.
- It’s important to note that most spell checkers, including the ones mentioned above, are based on the concept of edit distance, which means they may only sometimes provide accurate corrections.
- The Flan T5-based grammar checker is effective in correcting grammatical errors
- The grammar checker does not adequately handle abbreviations.
- Fine-tuning may be necessary to adapt the domain and improve performance.
Limitation
Spell Checker
Python-based spell checkers, such as pySpellChecker and TextBlob, are popular tools for identifying and correcting spelling errors. However, they do come with certain limitations:
- Language Support: Many Python spell checkers are primarily designed for English and may not support other languages, or their support for other languages might be limited.
- Contextual Mistakes: They are typically not very good at handling homophones or other words that are spelt correctly but used incorrectly in context (for example, “their” vs. “they’re” or “accept” vs. “except”).
- Grammar Checking: Python spell checkers are primarily designed to identify and correct spelling errors. They typically do not check for grammatical errors.
- Learning Capability: Many spell checkers are rule-based and do not learn from new inputs or adapt to changes in language use over time.
- Handling of Specialized Terminology: Spell checkers can struggle with domain-specific terms, names, acronyms, and abbreviations that are not part of their dictionaries.
- Performance: Spell checking can be computationally expensive, particularly for large documents, leading to performance issues.
- False Positives/Negatives: There is always a risk of false positives (marking correct words as incorrect) and false negatives (failing to identify wrong words), which can affect the accuracy of the spell checker.
- Dependency on Quality of Training Data: A Python spell checker’s effectiveness depends on its training data’s quality and comprehensiveness. If the training data might be biased, incomplete, or outdated, the spell checker’s performance may suffer.
- No Semantic Understanding: Spell checkers generally do not understand the semantics of the text, so they may suggest incorrect corrections that don’t make sense in the context.
Remember that these limitations are not unique to Python-based spell checkers; they are common to general spell-checking and text analysis tools. Also, there are ways to mitigate some of these limitations, such as using more advanced NLP techniques, integrating with a grammar checker, or using a custom dictionary for specialized terminology.
Grammar Checker
Limitation of grammar checker as follows.
- Training data quality and bias: ML-based grammar checkers heavily rely on training data to learn patterns and make predictions. If the training data contains errors, inconsistencies, or biases, the grammar checker might inherit those issues and produce incorrect or biased suggestions. Ensuring high-quality, diverse, and representative training data can be a challenge.
- Generalization to new or uncommon errors: ML-based grammar checkers tend to perform well on errors resembling patterns in the training data. However, they may struggle to handle new or uncommon errors that deviate significantly from the training data. These models often have limited generalization ability and may not effectively handle linguistic nuances or context-specific errors.
- Lack of explanations: ML models, including grammar checkers, often work as black boxes, making it challenging to understand the reasoning behind their suggestions or corrections. Users may receive suggestions without knowing the specific grammar rule or linguistic principle that led to the suggestion. This lack of transparency can limit user understanding and hinder the learning experience.
- Difficulty with ambiguity: Ambiguity is inherent in language, and ML-based grammar checkers may face challenges in resolving ambiguity accurately. They might misinterpret the intended meaning or fail to distinguish between multiple valid interpretations. This can lead to incorrect suggestions or false positives.
- Comprehension of context and intent: While ML-based grammar checkers can consider some contextual information, they may still struggle to understand the context and intent of a sentence fully. This limitation can result in incorrect suggestions or missing errors, especially in cases where the correct usage depends on the specific meaning or purpose of the text.
- Domain-specific limitations: ML-based grammar checkers may perform differently across various domains or subject areas. If the training data is not aligned with the target domain, the grammar checker might not effectively capture the specific grammar rules, terminology, or writing styles associated with that domain.
- Performance and computational requirements: ML-based grammar checkers can be computationally intensive, requiring significant processing power and memory resources. This can limit their scalability and efficiency, particularly when dealing with large volumes of text or real-time applications.
- Lack of multilingual support: ML-based grammar checkers often focus on specific languages or language families. Expanding their capabilities to support multiple languages accurately can be complex due to linguistic variations, structural differences, and the availability of diverse training data for each language.
It’s worth noting that the limitations mentioned above are not inherent to Python itself but are associated with ML-based approaches used in grammar checking, regardless of the programming language. Ongoing research and advancements in NLP and ML techniques aim to address these limitations and enhance the performance of grammar checkers.
Notebooks
Spell Checker: here
Grammar Checker: here
Conclusion
In conclusion, the development of a spell and grammar checker using Python showcases the power and versatility of this programming language in the realm of natural language processing. Through the utilization of Python packages such as TextBlob, symspellpy, and pyspellchecker, I have demonstrated the ability to create a robust system capable of detecting and correcting spelling and grammar errors in text.
The article has provided a comprehensive guide, guiding readers through the step-by-step process of implementing these packages and integrating them into a functional spell and grammar checker. By harnessing the capabilities of these Python libraries, we can enhance the accuracy and quality of written communication, ensuring that our messages are clear, professional, and error-free.
Moreover, the practical applications of spell and grammar checkers are vast and diverse. From academic writing and content creation to software development and beyond, these tools play a crucial role in improving language proficiency and ensuring the effectiveness of written content. As our reliance on digital communication continues to grow, the need for reliable language correction tools becomes increasingly apparent.
Looking ahead, the field of language processing and correction holds immense potential for further advancements and refinements. Python’s extensive ecosystem of packages provides a strong foundation for continued innovation in this domain. Future enhancements may include the incorporation of machine learning algorithms for more accurate error detection and correction, as well as the integration of contextual analysis to address nuanced grammatical issues.
In conclusion, the spell and grammar checker built with Python exemplifies the power of this language in enabling effective language correction. By leveraging the capabilities of Python packages, we can enhance communication, foster clarity, and elevate the overall quality of written content in various professional and personal contexts.
Please get in touch for more details here. If you like my article follow me on Medium for more content.
Previous blog: Chetan Khadke
References
- https://huggingface.co/pszemraj/flan-t5-large-grammar-synthesis
- https://paperswithcode.com/dataset/jfleg
- https://huggingface.co/datasets/jfleg
- https://textblob.readthedocs.io/en/dev/
- https://symspellpy.readthedocs.io/en/latest/examples/index.html
- https://pyspellchecker.readthedocs.io/en/latest/quickstart.html
Mind your words with NLP was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.