Loss functions are what make ANN (Artificial Neural Network) understand what is going wrong and how to get to that golden accuracy range, just like loss makes you cherish the profit and identify what went wrong.

Now coming to the mathematical definition of the loss function, it is used to measure the inconsistency between the predicted value (^y) and the actual label (y). It is a non-negative value, where the robustness of the model increases along with the decrease of the value of the loss function.
It’s straightforward actually, it’s basically how well your algorithm models the dataset, if its prediction is totally off, your loss function will output a higher number. If it is pretty good, it will output a lower number.
In this article, they are divided into three types
- Classification Losses
- Regression Losses
- Model Specific Losses
Let’s discuss them in-depth,
Classification Losses
In this, there are again various categories,
Binary Cross Entropy Loss / Log Loss
This loss function is mainly used in the training of a binary classifier, it compares each of the predicted probabilities to the actual class output which can be either 0 or 1.
It then calculates the score that penalizes the probabilities based on the distance from the expected value.
The mathematics behind it is discussed below,
That means how close or far from the actual value.
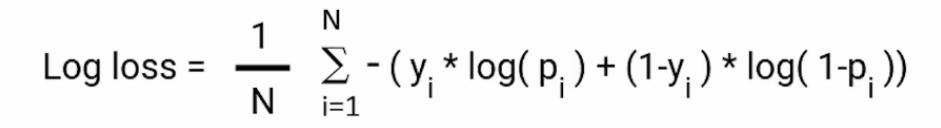
Here, pi is the probability of class 1, and (1-pi) is the probability of class 0.
When the observation belongs to class 1 the first part of the formula becomes active and the second part vanishes and vice versa in the case observation’s actual class are 0.
Implementation in Keras is shown below
Hinge Loss
It is used for classification problems and an alternative to cross — entropy, being primarily developed for support vector machines (SVM), difference between the hinge loss and the cross entropy loss is that the former arises from trying to maximize the margin between our decision boundary and data points.
Mathematically the equation is shown below,
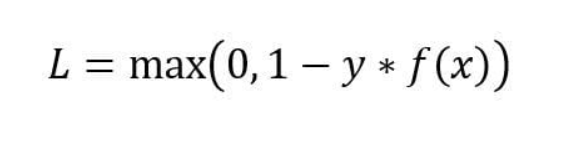
Implementation in Keras is below,
Categorical Cross Entropy
It is a SoftMax activation plus a Cross-Entropy loss. If we use this loss, we will train an image classifier using CNN to predict for each class present for example which bird class a bird image classifier belongs to .
It is used for multi-class classification.
Since activation functions are not discussed in this article and if you don’t know about it I i got you covered I have one more article covering activation functions in Deep Learning using Keras link to the same is below…
Types of Activation Functions in Deep Learning explained with Keras
Mathematically, the formula is shown below
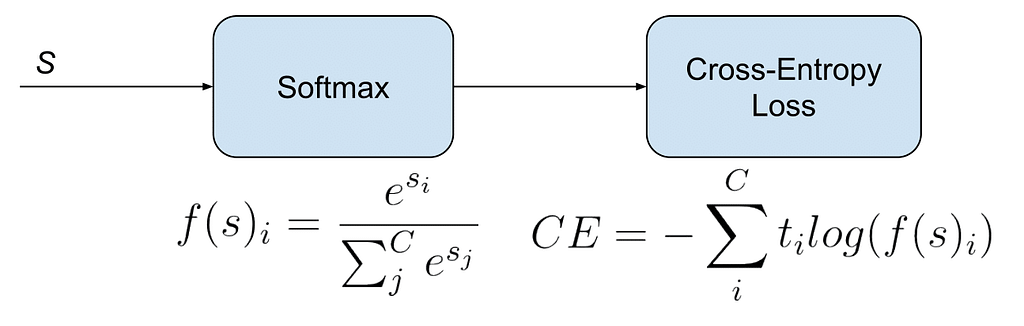
Implementation in Keras is shown below,
Sparse Categorical Cross Entropy Loss
Sparse CCEL(Categorical Cross Entropy Loss) and CCEL both compute categorical cross — entropy, the only difference being how the targets/labels should be encoded.
When using Sparse Categorical Cross entropy the targets are represented by the index of the category (starting from 0).
Your outputs have a shape of 4×2, which means you have two categories. Therefore, the targets should be a 4 dimensional vector with entries that are either 0 or 1. This is in contrast to Categorical Cross entropy where the labels should be one-hot encoded.
Mathematically, the equation is
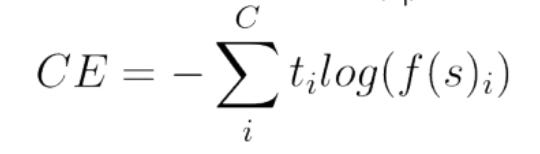
When to use which,

Implementation in Keras is shown below,
Kullback — Leibler Divergence Loss
Simply put, it is the measure of how a probability distribution differs from another probability distribution.
Mathematically, it can be explained using
KL divergence between two distributions P and Q.

The “||” operator indicates “divergence” or Ps divergence from Q.
KL divergence can be calculated as the negative sum of the probability of each event in P multiplied by the log of the likelihood of the event in Q over the probability of the event in P.

Implementation in Keras is as follow,
Regression Losses
In this, there are again various categories,
MSE ( Mean Square Error / Quadratic Loss / L2 Loss)
It is the average squared difference between observed and predicted values. e.g. in Linear Regression, we find lines that best describe the provided data points. Many lines can describe data points but which line to choose which best describes it can be found using MSE.
In below Diagram , predicted values are on the lines and actual values are shown by small circles.
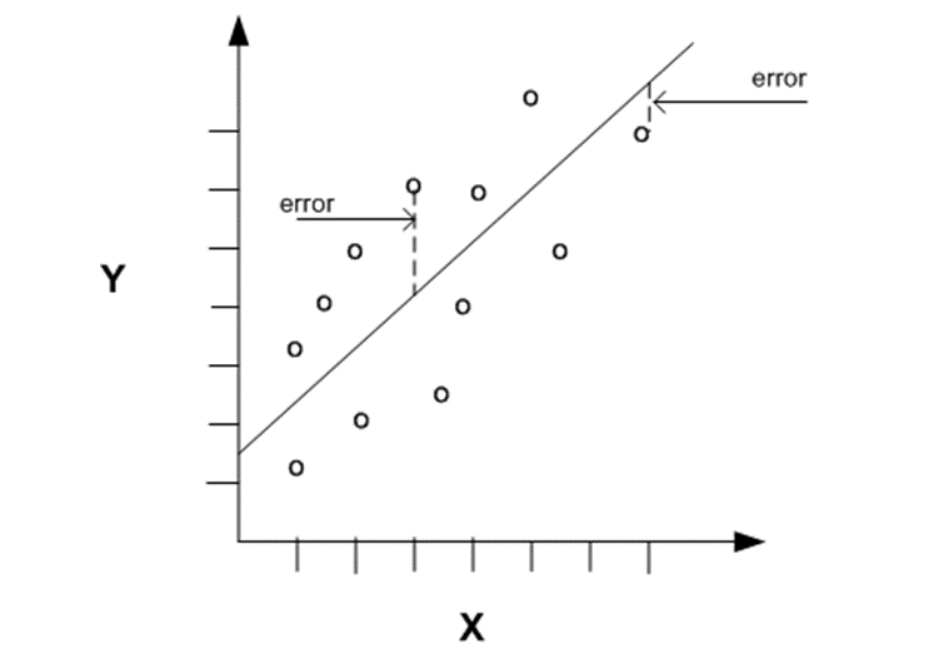
Error is the distance between data point and fitted line.
Mathematically, it can be stated as
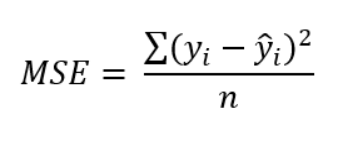

Implementation in Keras is shown below,
Mean Absolute Error / L1 Loss
Now we move on to Absolute values no messing around, all round up now!
It computes the mean of squares of errors between labeled data and predicted data. It calculates the absolute difference between the current output and the expected output divided by the number of output.
Unlike Mean Squared Error , its not sensitive towards outliers.
Mathematically , it can be written as
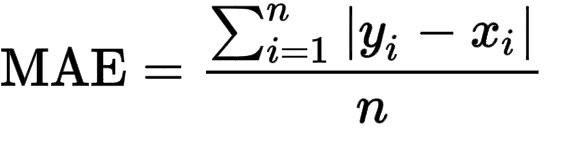
As seen in the formula modules is added giving only the absolute values for the error.
Implementation in Keras is shown below,
Huber Loss / Smooth Mean
The best of both of worlds, iOS & Android both phones together? Nah..
Its Huber Loss function , it combines MSE and MAE ,if loss value is greater than delta use MAE, if less use MSE.
Mathematically , it can be written as
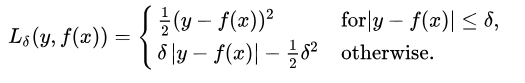
Implementation in Keras is below
Now coming to Model Specific Losses they are mentioned with models in which they are used below,
MinMax (GAN Loss)
Generative Adversarial Networks uses this particular Loss and its a simple one ( that’s what they say).
Before this loss a little insight on GAN is needed so lets describe it in summary below
- Two Neural Networks are involved.
- One of the networks, the Generator, starts off with a random data distribution and tries to replicate a particular type of distribution.
- The other network, the Discriminator, through subsequent training, gets better at classifying a forged distribution from a real one.
- Both of these networks play a min-max game where one is trying to outsmart the other.
Now coming back to min-max loss, mathematically its equation is
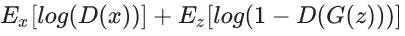
The generator tries to minimize this function while the discriminator tries to maximize it and it saturates for the generator, making it stop training it is behind discriminator …sad generator noises….
This can be further categorized into two parts 1) Discriminator Loss and 2) Generator Loss
Discriminator Loss
Discriminator train by classifies both the real data and the fake data from the generator.
It penalizes itself for misclassifying a real instance as fake, or a fake instance (created by the generator) as real, by maximizing the below mentioned function.
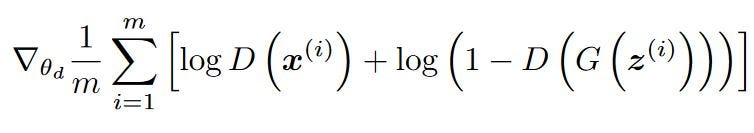
- log(D(x)) refers to the probability that the generator is rightly classifying the real image,
- maximizing log(1-D(G(z))) would help it to correctly label the fake image that comes from the generator.
Generator Loss
While the generator is trained, it samples random noise and produces an output from that noise. The output then goes through the discriminator and gets classified as either “Real” or “Fake” based on the ability of the discriminator to tell one from the other.
The generator loss is then calculated from the discriminator’s classification — it gets rewarded if it successfully fools the discriminator, and gets penalized otherwise.
The following equation is minimized to training the generator,
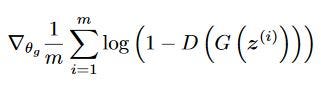
This whole implementation of a Deep GAN Network along with loss in mentioned below as the loss is defined with respect to the model whole implementation needs to be referred.
docs/dcgan.ipynb at master · tensorflow/docs
Focal Loss (Object Detection)
It is extension of cross entropy loss function and it down-weight easy examples and focus training on hard negatives.
Focal loss applies a modulating term to the cross entropy loss in order to focus learning on hard misclassified examples. It is a dynamically scaled cross entropy loss, where the scaling factor decays to zero as confidence in the correct class increases.
Mathematics coming right up,
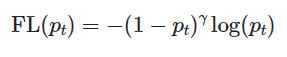
Focal Loss adds a factor (1−pt)^γ to the standard cross entropy criterion. Setting γ>0 reduces the relative loss for well-classified examples (pt>.5), putting more focus on hard, misclassified examples. Here there is tunable focusing parameter γ≥0.
Implementation in Keras is shown below,

The whole notebook with each losses implemented is mentioned below,
References
https://medium.com/nerd-for-tech/what-loss-function-to-use-for-machine-learning-project-b5c5bd4a151e
https://www.analyticsvidhya.com/blog/2020/08/a-beginners-guide-to-focal-loss-in-object-detection/
If you liked this article and want to read more like it , you can visit my medium profile and if you wish to connect here is my LinkedIn profile
https://www.linkedin.com/in/tripathiadityaprakash/
Types of Loss Functions in Deep Learning explained with Keras. was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.