I was doing sentiment analysis for a data journalism article for a bootcamp’s final project. The tweets are Indonesian tweets about Kominfo’s recent blocking of Steam (and some other overseas platforms). You can read my article here (it’s only in Indonesian though). By the way, I’m using Python on Google Colab.
At first, I was using TextBlob as explained here, but the result was bad. I was sure that at least for #BlokirKominfo tweets, it must be mostly negative. Yet, it was mostly neutral, or positive, depending on where you draw the lines (because TextBlob outputs polarity in range of -1.0 to +1.0). Well, TextBlob only supports English, so the tweets were translated into English. Also, TextBlob is rule-based, while state-of-the-art NLP uses neural network. But it’s not like I can just train my own neural network model in a few days. I’m a total noob at NLP. Luckily, Huggingface has a lot of pretrained model available for free, and there exists an Indonesian one.
So let’s get started.
1. Registering for a Twitter developer account
Twitter now provides an easy and free developer account registration. Of course, it will have a lot of limits. For example, the API calls you can do within 15 minutes is limited. You also can only query for the past 7 days. If you need more, you can upgrade your essential (basic) account by paying or by applying for an elevated or academic account. If you just need more API calls, go for the elevated one, since it’s still fairly easy. It also gives you access to V1 API. By default, you have access to V2 API and it’s still incomplete, for example, you can’t get trending data. If you need to go further than 7 days, go for the academic one, but it’s quite hard, since you need to have a legit research as a researcher or graduate student.

Okay, so how to get a developer account? Go to https://developer.twitter.com/ , click sign up at the upper right corner, then login with your Twitter account. You’ll then get a form. Fill the form, submit it, and you’re done. Make sure the save all of the tokens and secrets. But here we’ll only be using the bearer token.
2. Get tweets
First, you need to install Tweepy. You can do this using pip.
pip install tweepy
If you’re using google colab or jupyter, put a “!” at the front.
!pip install tweepy
Next, import it. “tw” here is just an alias to make it shorter.
import tweepy as tw
Now we create a client object using the bearer token. The wait_on_rate_limit argument being True tells Tweepy to wait for cooldown if you went past API rate limits.
client = tw.Client(
bearer_token=bearer_token,
wait_on_rate_limit=True
)
Then we can finally query tweets. We’ll be using search_recent_tweets. If you have academic account or paid account that supports past 7 days, you can use search_all_tweets instead.
result = client.search_recent_tweets(
query,
start_time=start_time,
end_time=end_time,
max_results=max_results,
next_token=next_token,
tweet_fields=tweet_fields
)
2.1. Arguments explanation
query would be your search query; it’s a required parameter. You can add “-is:retweet” at the end of your query to exclude retweets.
start_time and end_time defines the time window of your search. They’re in ISO 8601/RFC 3339 datetime format, which is YYYY-MM-DDTHH:mm:ssZ. It’s in UTC, so make sure you subtract your timezone difference to it. West Indonesia time is UTC+7, so today at 00:00 would be yesterday at 17:00 in UTC.
max_results is the max number of tweets in one API call. You can only have it 100 at most. If your query yields more than that, you’ll get a “next_token” attribute in the result’s metadata (not null). You can provide this next_token to get the “next page” of your query. If there’s no more tweets left to retrieve, next_token will be null. This should perfectly fit in a do-while loop, but python doesn’t have that, so let’s just set up a flag.
first = True
next_token = None
data = [] # This is just an example of combining the result
while first or next_token:
result = client.search_recent_tweets(...)
data = result.data
next_token = result.meta["next_token"]
# This is just an example of combining the result
data += data
...
tweet_fields tells the API which tweet attributes/fields to retrieve. In Tweepy, it’s a list of strings or a comma-separated string of field names. For example, if you want to retrieve the like count etc, you’ll want the public_metrics field. In my project, I used these fields:
tweet_fields=[
"author_id",
"conversation_id",
"created_at",
"id",
"lang",
"public_metrics",
"text"
]
Well, that’s all for the tweet search API.
3. Sentiment Analysis of Indonesian Tweets
Next, we’ll be using BERT to do sentiment analysis. We’ll use this model by mdhugol. It’s a sentiment classification model based on IndoBERT. It classifies text into positive, neutral, and negative ones (in this order of label). The website provides a field for you to try the model easily.
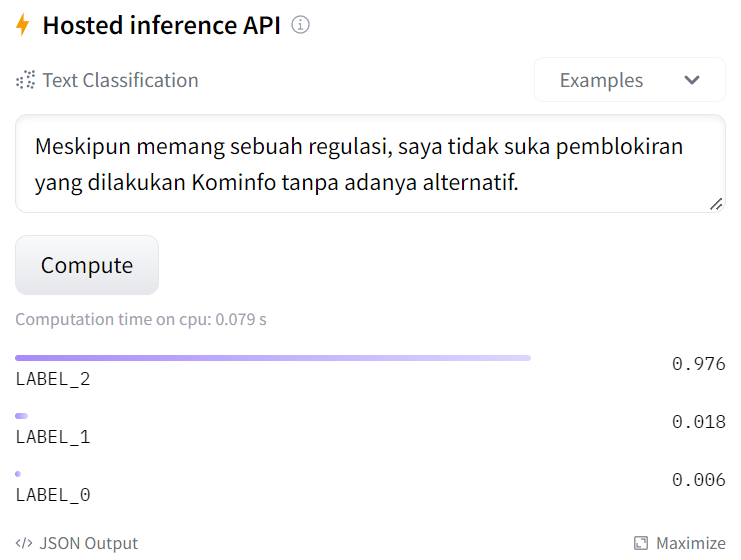
3.1. Init
Okay, for the model we’ll need to install transformer and emoji. Transformer package will be for the model, while emoji will be used to convert emojis into text that represents it. Just like before, add “!” at the front if you’re using google colab or jupyter.
pip install transformers emoji --upgrade
Next, we import them and define some constants. In addition to those packages, we’ll also use regex and html for cleaning.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
import emoji
import re
import html
pretrained_id = "mdhugol/indonesia-bert-sentiment-classification"
label_id = {'LABEL_0': 'positive', 'LABEL_1': 'neutral', 'LABEL_2': 'negative'}
3.2. Text Cleaning
Before we do the sentiment analysis, we first need to clean the text. It’s not much, just removing or replacing some stuff. This function is based on preprocessing of indoBERTweet by indolem. It replaces user tags with @USER and urls with HTTPURL.
In addition to that, I’ll be replacing emojis with their text representation using emoji.demojize so the model will take emojis into account when determining the sentiment. However, it makes tweets longer, specially on those that spammed emojis. Meanwhile by default the model doesn’t support very long text. Twitter already has tweet length limit and it fits the model, but due to converting emojis, some tweets get very long. So I’m mitigating this by limiting repeating emojis to 3 repetition at most. I use regex to do this.
tweet = emoji.demojize(tweet).lower()
tweet = re.sub(r"#w+", "#HASHTAG", tweet)
tweet = re.sub(r"(:[^:]+:)1{2,}", r"111", tweet)
tweet = re.sub(r"(:[^:]+:)(:[^:]+:)(1+2+){2,}", r"121212", tweet)
Lastly, I unescape HTML-escaped characters using html.unescape. When using TextBlob, I found that some tweets uses escaped HTML characters. It made TextBlob throw an error. Not sure what it does to BERT, but I’ll just unescape them.
Anyway, here’s the full preprocessing functions. Just use the preprocess_tweet function.
def find_url(string):
# with valid conditions for urls in string
regex = r"(?i)b((?:https?://|wwwd{0,3}[.]|[a-z0-9.-]+[.][a-z]{2,4}/)(?:[^s()<>]+|(([^s()<>]+|(([^s()<>]+)))*))+(?:(([^s()<>]+|(([^s()<>]+)))*)|[^s`!()[]{};:'".,<>?«»“”‘’]))"
url = re.findall(regex,string)
return [x[0] for x in url]
def preprocess_tweet(tweet):
tweet = emoji.demojize(tweet).lower()
tweet = re.sub(r"#w+", "#HASHTAG", tweet)
tweet = re.sub(r"(:[^:]+:)1{2,}", r"111", tweet)
tweet = re.sub(r"(:[^:]+:)(:[^:]+:)(1+2+){2,}", r"121212", tweet)
new_tweet = []
for word in tweet.split():
if word[0] == '@' or word == '[username]':
new_tweet.append('@USER')
elif find_url(word) != []:
new_tweet.append('HTTPURL')
elif word == 'httpurl' or word == '[url]':
new_tweet.append('HTTPURL')
else:
new_tweet.append(word)
tweet = ' '.join(new_tweet)
tweet = html.unescape(tweet)
return tweet
3.3. BERT model
Okay, now that the text are good, we can do the sentiment analysis. We create a tokenizer and a model using the name of the pretrained model (pretrained_id). It will download from Huggingface so you need internet connection. It’s quite big, but Google Colab runs on Google’s servers and uses Google’s fast connection. Next, we create sentiment-analysis pipeline using the model and tokenizer.
tokenizer = AutoTokenizer.from_pretrained(pretrained_id)
model = AutoModelForSequenceClassification.from_pretrained(pretrained_id)
sentiment_analysis = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
Then, we just use the pipeline and convert the result label.
text = preprocess_tweet(text)
result = sentiment_analysis(text)
status = label_id[result[0]['label']]
score = result[0]['score']
print(f'Text: {text} | Label : {status} ({score * 100:.3f}%)')
That’s it. Really. Sentiment analysis done. Huggingface pretrained models made it very easy to do. Well, if you can find the right model that fits your use case, that is. Otherwise you’ll have to adjust it or even retrain the model.
4. Using the Proper Model for the Tweet Language
Despite the query being an Indonesian event, not all tweets are in Indonesian. We can use the “lang” field of the tweet to know what language it is in (according to Twitter). With that, we can do sentiment analysis of a tweet using the proper model for the tweet’s language. In my project, I used BERTsent by rabindralamsal for English tweets. However, do note that different models may use different labels. BERTsent, for example, also classifies tweets into positive, neutral, and negative, but in the opposite order. In the Indonesian model, LABEL_2 means negative, but in BERTsent, it means positive. Here’s the constants by the way:
pretrained_en = "rabindralamsal/BERTsent"
label_en = {'LABEL_0': 'negative', 'LABEL_1': 'neutral', 'LABEL_2': 'positive'}
Closing
Well, that’s about it. It took a while figuring out how to do it, but once you know how, it’s actually rather easy. But of course, I didn’t do much text preprocessing. I didn’t make the model myself either. Actually, I don’t even have NLP basics, so please correct me if I wrote something wrong. Or, maybe, if you want to add something, please just do so in the comments. Thanks for reading.
Indonesian Twitter Sentiment Analysis using Pretrained Neural Network Transformer (BERT) was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.