Expand your NLP portfolio using BERT and Haystack to answer all your questions!
If you’re trying to learn Natural Language Processing (NLP), make a Discord Bot, or are just interested to play around with Transformers for a bit, this is the project for you!

In this example, we will create a Chatbot that knows everything about Dragon Ball, but you can do about anything you want! It can be a chatbot that answers questions about another series, a university course, the laws of a country, etc. Firstly, let’s see how that is possible with BERT.
How a BERT works as a Chatbot
BERT is a Machine Learning technique for NLP created and published by Google in 2018. In the first phase, the model is pre-trained on a large language dataset in a semi-supervised way.
In this phase, the model cannot answer questions yet, but it learned contextual embeddings for words.

In the second phase, BERT is then finetuned for a specific task. Because we are trying to build a Chatbot, we need a model that is finetuned on a Question Answering task.

After the model is finetuned for Question Answering, we have to provide the Input Dataset for the model to know where to extract its answers from. Finally, the user can then input a question. The model will extract the answer from the input dataset.
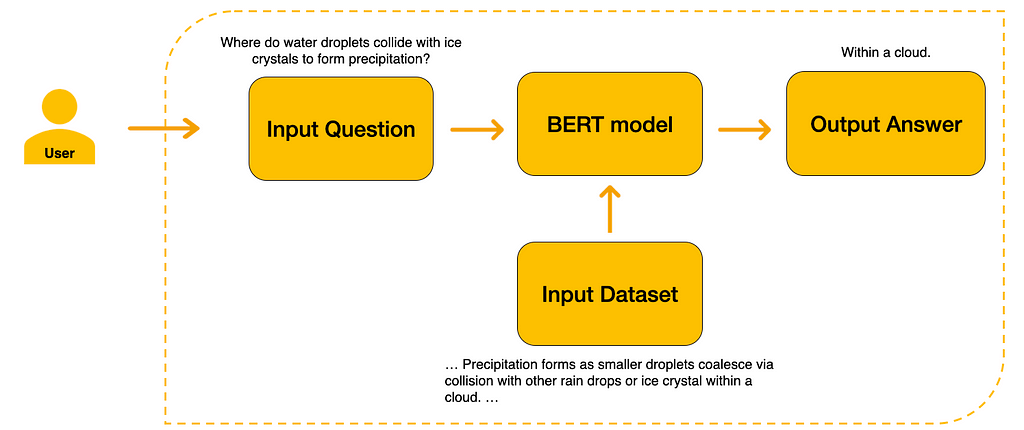
As such, first of all, we need to get an Input Dataset from where the model will extract its answer from.
Fetching the Data
In this example, our chatbot will be a Dragon Ball Master, so we will fetch the data from the Dragon Ball Wiki with BeautifulSoup. Scraping isn’t the focus of this post, so we are just going to brute force it a little bit to get all the data we need.

{kind=link}
We fetch the data of the chapters and also of the different series (Dragon Ball Z, Dragon Ball GT, etc). The most important information that we will take is what actually happens in each chapter and, through the pages of the different series, we also have other types of information (creator, production company, dates of airing, etc).
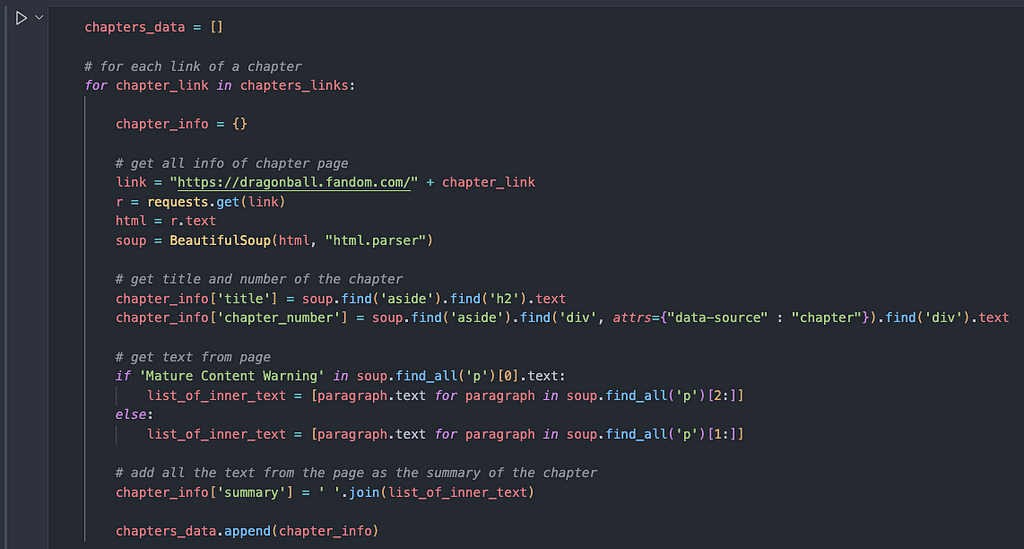
After getting all the summaries of each episode, Haystack needs the data to be formatted as a list of dictionaries, which have two major keys. One of the keys is called “content”, where the model will extract all the information needed to answer all questions. The other key is called “meta” and has a nested dictionary with all the metadata you need. In this example, I passed a dictionary with the title and number from the episode which the summary was extracted from.

Now that we have all the information about what happens in the series, we need to initialize our model!
Initiating BERT
For this part, I will use Google Collab because of two reasons:
- it is much easier to setup Haystack: Haystack is a library for NLP which has a lot of dependencies and sometimes making it work on your personal computer is not very smooth, especially for beginners who are not used to set up environments;
- we will use a BERT model, which is a big model that works much faster with a GPU — which Google Colab provides for free!

{kind=link}
We need to choose a Retriever and a Reader to use. The Retriever is a lightweight filter that goes through our whole database of documents and chooses an X number of documents that might answer the question the user is posing. In this case, we will ask the Retriever to return 10 documents.

The Retriever passes these 10 documents to the Reader. In this case, we will use a BERT as our Reader. More specifically, we will use an English BERT model that is already finetuned for Extractive Question Answering. In essence, that means that the model was pre-trained in the English language and then was trained for Extractive QA in the last layer of training. Because the Dragon Ball data is already in English, the model is already prepared out of the box for answering our questions!
PS: If you have data in another language, you can search for a model that is trained in that language in HuggingFace.
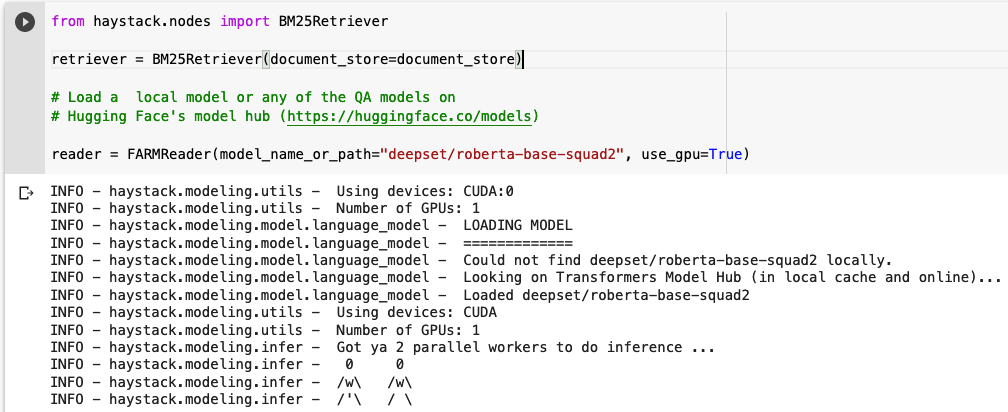
We will ask the model to return the 5 most probable right answers from the 10 documents most probably to have the answer! Remember: the Retriever finds the right documents and the Reader finds the exact answer (in this case, our reader is roberta-base-squad2)! This is the output of the model after inputting a simple question about Dragon Ball:
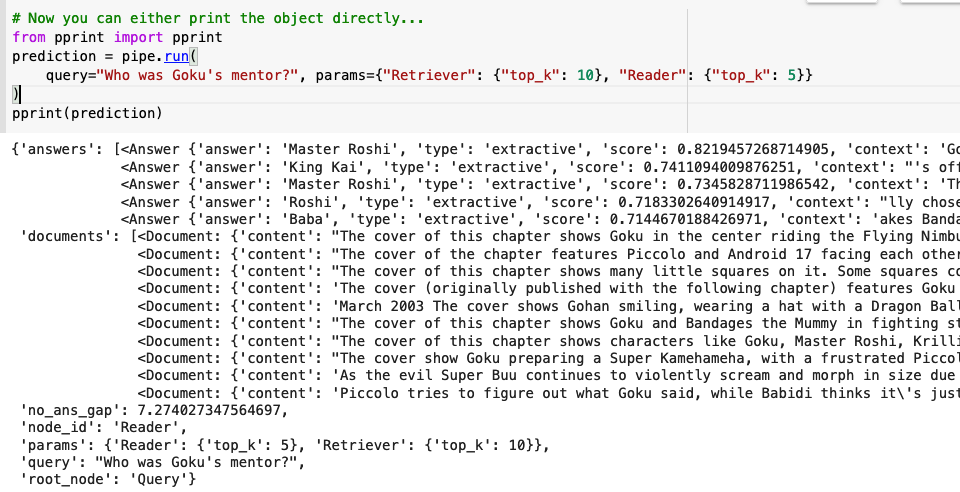
The model got the answer right! The mentors of Goku were Master Roshi and King Kai!

Again, this is right out of the box, we didn’t have to train any model on our data!
Testing our Chatbot
After creating a function that lets our output be prettier, let’s see the results!
Let’s ask it who Vegeta is married to:

It got it right! Its first answer was Bulma! Let’s try other questions and see the results:



The model is answering quite well to a lot of the questions!

But if we add some variation in the way we ask some questions, it starts being not quite right…


These are just some examples of how the model is still not perfect.

{kind=link}
No worries, because we can train it further on our data if we want! Haystack has a simple tutorial on how to do this also. However, that could be its entire new post. If you would find it useful, you can send me a message or a comment and I will try to create a post explaining it step by step.
Further Work
The Haystack library has very nice documentation and this post was actually based on one of their tutorial notebooks. We can try to add more data about other series and try to see if the model retains its performance. Here is the link to the Github Repository of the project if you want to access the notebooks used.
I hope you enjoyed creating your first-ever chatbot with BERT 🙂

Build a Chatbot about your favorite series in 30 minutes was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.