Introduction
Transformer models have taken the world of Natural Language Processing by storm. This post is intended to build a simple QnA chatbot. We will first build a knowledge base based on the training set. We will use distilbert-base-uncased transformer model to calculate the sentence vectors for each of the sentences present in the knowledge base. These sentence vectors capture the context of the sentence and in turn, help to understand the sentence.
We will store the sentence vectors in Mongo Database. When the user sends a query, a vector representation of the query will be calculated. Using the cosine similarity, we will find the sentence vector from the knowledge base that matches the most with the input query vector. The intent of the matching sentence will be recognized and the output will be displayed to the user based on the responses mentioned for that intent.
Distilbert-base-uncased
DistilBERT is a small, fast, cheap, and light Transformer model trained by distilling BERT base. It has 40% fewer parameters than Bert-base-uncased, runs 60% faster while preserving over 95% of BERT’s performances as measured on the GLUE language understanding benchmark.
Pytorch
PyTorch is an open-source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing, primarily developed by Facebook’s AI Research lab (FAIR). It is free and open-source software.
PyTorch provides two high-level features:
1. Tensor computing (like NumPy) with strong acceleration via graphics processing units (GPU)
2. Automatic differentiation system
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Installation of Packages
Transformers: This library brings together over 40 state-of-the-art pre-trained NLP models (BERT, GPT-2, Roberta, etc..)
# Install Transformers
!pip install transformers==3
Import Libraries
Importing the libraries that are required to perform operations on the dataset.
import random
import numpy as np
import pandas as pd
import torch
from sklearn.metrics.pairwise import cosine_similarity
Importing the DistilBertModel and DistilBertTokenizer to calculate the sentence vectors.
from transformers import DistilBertModel, DistilBertTokenizer
tokenizer = DistilBertTokenizer.from_pretrained(‘distilbert-base-uncased’)
model = DistilBertModel.from_pretrained(“distilbert-base-uncased”)
Reading the dataset
df = pd.read_excel(r’D:MLML_RevDatasetsKB.xlsx’)
print(df.head())
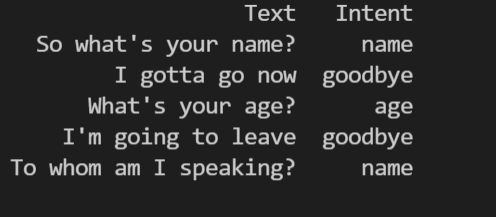
sentences = df[‘Text’]
l_intent = df[‘Intent’]
Generate sentence embeddings for the sentences in the dataset
def get_embedding(sents):
# initialize dictionary: stores tokenized sentences
token = {‘input_ids’: [], ‘attention_mask’: []}
for sentence in sents:
# encode each sentence, append to dictionary
new_token = tokenizer(sentence, max_length=128,
truncation=True, padding=’max_length’,
return_tensors=’pt’)
token[‘input_ids’].append(new_token[‘input_ids’][0])
token[‘attention_mask’].append(new_token[‘attention_mask’][0])
# reformat list of tensors to single tensor
# combining a list of tensors into a 2D single tensor
token[‘input_ids’] = torch.stack(token[‘input_ids’])
token[‘attention_mask’] = torch.stack(token[‘attention_mask’])
output = model(**token)
embeddings = output[0]
print(embeddings.shape)
att_mask = token[‘attention_mask’]
print(att_mask.shape)
mask = att_mask.unsqueeze(-1).expand(embeddings.size()).float()
print(mask.shape)
mask_embeddings = embeddings * mask
print(mask_embeddings.shape)
summed = torch.sum(mask_embeddings, 1)
print(summed.shape)
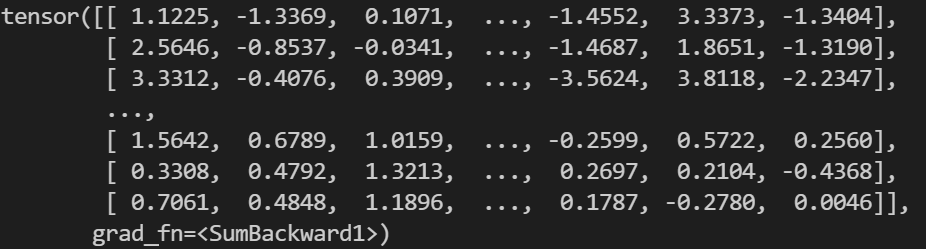
print(summed)
summed_mask = torch.clamp(mask.sum(1), min=1e-9)
print(summed_mask.shape)
mean_pooled = summed / summed_mask
print(mean_pooled)
# convert from PyTorch tensor to numpy array
mean_pooled = mean_pooled.detach().numpy()
return mean_pooled
Generate Embeddings
mean_pooled = get_embedding(sentences)
Embeddings shape

Attention mask shape

Mask shape

Mask Embeddings shape

Summed shape

Summed
Summed mask shape

Mean pooled
Mean pooled shape

Storing the results
result = []
for i in range(len(sents)):
d = {}
d[‘Text’] = sents[i]
d[‘Intent’] = l_intent[i]
d[‘Embedding’] = mean_pooled[i].tolist()
result.append(d)
Building the knowledge base
Storing the sentences and vectors in Mongo DB
Importing the required library
import pymongo
Establish a connection to the DB
DEFAULT_CONNECTION_URL = “mongodb://localhost:27017/”
DB_NAME = “KB”
# Establish a connection with mongoDB
client = pymongo.MongoClient(DEFAULT_CONNECTION_URL)
Create a database and the table
data_base = client[DB_NAME]
collection_name = ‘QuestionAnswer’
collection = data_base[collection_name]
Insert the records into the database
records = collection.insert_many(result)
When the user enters the query:
1. Calculate the sentence vector of the query
2. Identify the most matching sentence from the knowledge base using cosine similarity
def calculate_similarity(query):
mean_pooled = get_embedding([query])
question = []
similarity = []
intent = []
for rec in collection.find():
question.append(rec[‘Text’])
intent.append(rec[‘Intent’])
cos_sim = cosine_similarity([mean_pooled[0]],
[np.fromiter(rec[‘Embedding’], dtype=np.float32)])
similarity.append(cos_sim)
index = np.argmax(similarity)
recognized_intent = intent[index]
return recognized_intent
Intents JSON file
Here we set up an intents JSON file that defines the intentions of the chatbot user.
For example:
A user may wish to know the name of our chatbot; therefore, we have created an intent called name.
A user may wish to know the age of our chatbot; therefore, we have created an intent called age.
In this chatbot, we have used 5 intents: name, age, date, greeting, and goodbye. When the user enters any input, the intent will be recognized by the bot.
Within this intents JSON file, alongside each intents tag, there are responses. For our chatbot, once the intent is recognized the response will be randomly selected from the static set of responses associated with each intent.
# used a dictionary to represent an intents JSON
data = {"intents": [
{"tag": "greeting",
"responses": ["Howdy Partner!", "Hello", "How are you doing?", "Greetings!", "How do you do?"],
},
{"tag": "age",
"responses": ["I am 24 years old", "I was born in 1996", "My birthday is July 3rd and I was born in 1996", "03/07/1996"]
},
{"tag": "date",
"responses": ["I am available all week", "I don't have any plans", "I am not busy"]
},
{"tag": "name",
"responses": ["My name is Kippi", "I'm Kippi", "Kippi"]
},
{"tag": "goodbye",
"responses": ["It was nice speaking to you", "See you later", "Speak soon!"]
}
]}
Generate the response to the user’s query
def get_response(intent):
for i in data[‘intents’]:
if i[“tag”] == intent:
result = random.choice(i[“responses”])
break
return result
Now its time to test our chatbot
recognized_intent = calculate_similarity('Hello my friend')
print(f"Intent: {recognized_intent}")
print(f"Response: {get_response(recognized_intent)}")

recognized_intent = calculate_similarity('What do people call you')
print(f"Intent: {recognized_intent}")
print(f"Response: {get_response(recognized_intent)}")

recognized_intent = calculate_similarity(‘How old are you’)
print(f”Intent: {recognized_intent}”)
print(f”Response: {get_response(recognized_intent)}”)

recognized_intent = calculate_similarity(‘what are your weekend plans’)
print(f”Intent: {recognized_intent}”)
print(f”Response: {get_response(recognized_intent)}”)

recognized_intent = calculate_similarity(‘Catch you later’)
print(f”Intent: {recognized_intent}”)
print(f”Response: {get_response(recognized_intent)}”)

Don’t forget to give us your 👏 !




QnA Chatbot using sentence simi was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.