
Each second countless amount of data is created by social media users on the internet, for instance, since 2013, the number of Tweets each minute has increased 58 % to more than 474000 Tweets per minute in 2019. Instagram users upload over 100 million photos and videos everyday. Due to this constant flow of data the internet turns out to be the best data source that can be encountered, thus being the object of numerous analysis that can be performed using artificial intelligence.
One of the most famous platforms used these days to share media content is YouTube. YouTube is the preferred way that people use to share content, on this platform it can be encounter videos about endless topics so each video can reach millions of people that can react in a variety of ways. The purpose of this post is truly worth it. since, we will learn how to use data analysis, machine learning, and data mining techniques to analyze videos on YouTube.
Knowing the inside of a website.
First things first. Before performing any analysis, we need to collect the data of interest. Performing analysis over websites can be a bit challenging since in these cases there is not a data set or formal database that can be used to perform such analysis. To perform these studies we need to extract the data directly from the website delving into the deepest parts of it, the process to navigate into the website is called web scraping.
A brief introduction to Selenium.
Selenium is a web scraping Python library that allows us to interact with websites and extract data from them using Python code. Selenium serves as an interface between Python and the website using a web browser like Firefox or Chrome as a web engine. Let’s see a simple example to get an idea about all the potential this library can unfold.
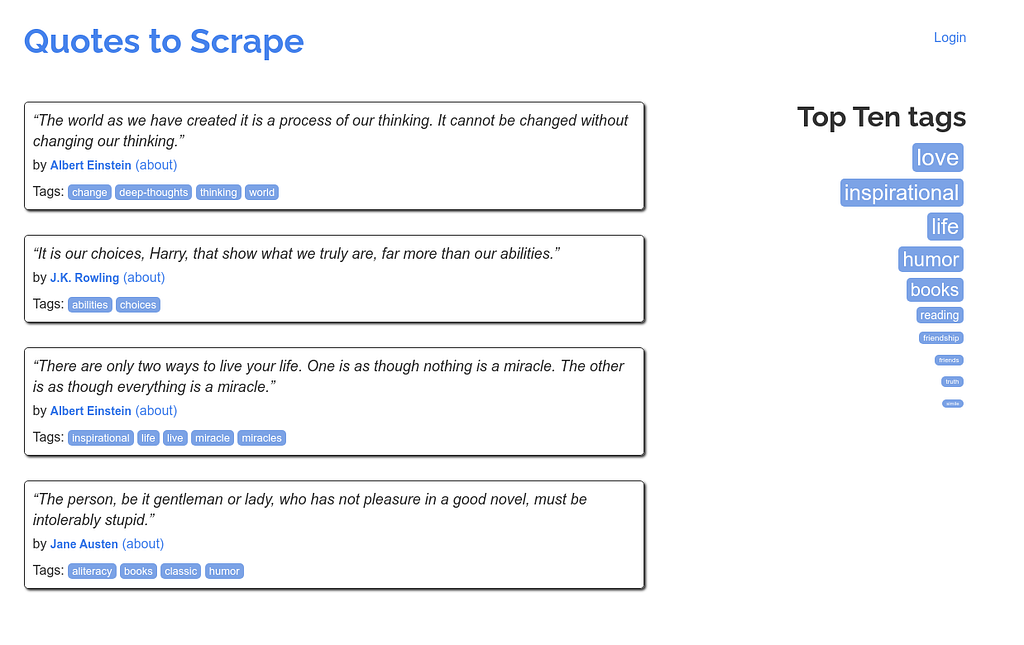
The website https://quotes.toscrape.com/ will be our target to explore the different methods we can use to extract data from this page. The page looks like this:
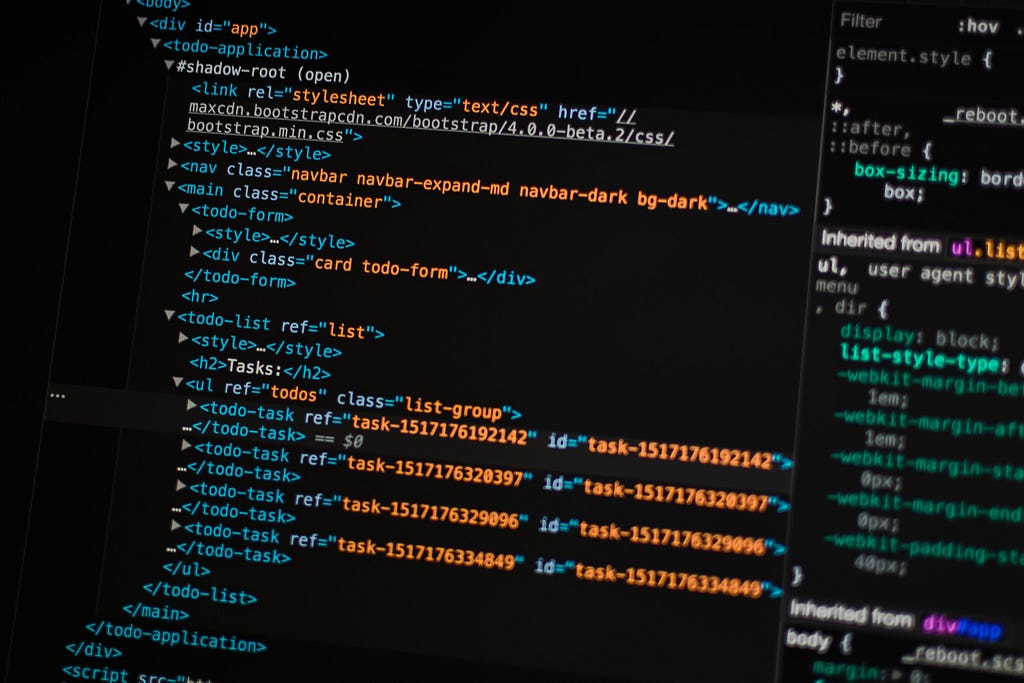
The goal is to obtain quotes from the website, to do that we need to understand what is behind this website, thus we should dive into the html code that structures every website on the internet. Using the developer tools that most browsers have, we can uncover the HTML and CSS code, said that, the inner structure of our website looks like this:

In the image above it is shown part of the HTML code within the website, it can be observed a kind of tree structure where each node is represented by a HTML tag. HTML tags are like keywords that define how the web browser will format and display the content. With the help of tags, a web browser can distinguish between HTML content and simple content.
The text we want to obtain is within a span tag, which has a class named “text”, the tag span and therefore the “text” class are within a div section with a class named “quote”. We can see that the class “quote” is a container for each quote on the page. Known this, we can easily infer that each quote is within a tag named “text”, which in turn is inside a div tag with a class named “quote”. Let’s use this to get the first quote with Selenium. The code is shown below.
Selenium has a class WebDriver that will allow us to interact with websites. in this particular case, we are going to use Firefox as an interface between Python and the website. By default, when you use the WebDriver class, it opens up your browser.
Preventing the browser from loading
Since we are not interested in opening the browser when the WebDriver is executed, the lines the code 4 and 5 disable this event creating an option that is passed as an argument of the WebDriver instantiation done at the line of code 7.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
The first quote
The driver.get method will then navigate to the page given by the URL. WebDriver will wait until the page is fully loaded before returning control to the script. Finally, WebDriver offers a number of ways to find elements by using one of the find_element_by_* methods.
Since we already know the name of the class that contains the quote, we will use it using the method find_element_by_class_name(class_name) using the class name as a parameter. Then we extract the text property from the object returned by the method to obtain the quote.
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
Getting the rest of the quotes.
This method obtains the first quote by default, however, we are getting the first quote just because it appears in the first element with the text class. if we want to obtain all the quotes on the first page, the driver object provides a set of methods that extract all the elements on the website with the class name indicated. In this scenario, the ways to find elements would be done using the find_elements_by_* methods. Notice the plural on the word “elements”.
If we want to obtain all the quotes from the first page, it is enough to implement a for loop using the method mentioned before. For example, the code shown below will extract all the quotes from the first page.
Diving into a YouTube page video.
Try to open a YouTube video and you will notice that the website does not load the comments until you scroll down over the page. Therefore, if we try to use the previous script we will have nothing but the data referring to the video player, which is loaded when the website starts.
Using Selenium to execute JavaScript code.
Fortunately, one of the advantages of selenium is that it allows us to navigate into the website using Python code in the same way as we would with the web browser. Using the following script we can scroll down over the web page.
The key to moving through the web page is the ability of Selenium to execute JavaScript code by using the method execute_script . Consequently, we can take advantage of all the dynamic properties within a web page. Thus, the script shown above gets information about the web page, specifically, the scrollHeight property, which indicates the height of the document element.
Then, it is time to scroll down over the web page using the method window.scrollTo(0, height) . Finally, the while loop will continue scrolling down to the point where it is impossible to continue doing this, that is, the property scrollHeight will not change anymore, indicating the page is fully loaded.
The comment section.
If we look at the HTML code that generates the comment section we will see the following structure.
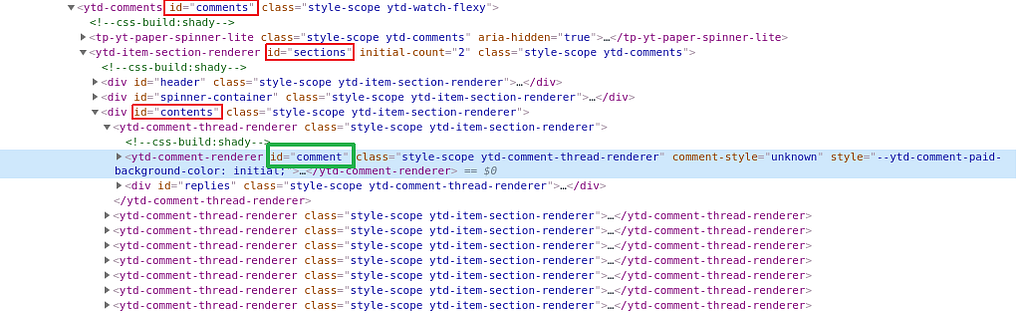
It can be observed that the comments are inside a structure which starts with the id “comments”, then if we continue unfolding the structure, we realize that all the comments are within a div tag that contains the id “contents”, hence each comment is identified with the classes style-scope and ytd-comment-thread-renderer
Within this section we encounter two subsections that store data about the comment. The first section is identified with the id: “comment”, the second section identified with the id “replies” stores information about the replies made on that specific comment. Since the interest holds just above the text written about the video, let us concentrate on the first section.

As we unfolded the comment section we see two new sections, the first is identified with the id “paid-comment-images” and the other with id “body”, the last one contains the information that we are looking for, so unfolding this section we encounter three subsections with ids “author-thumbnail”, “main”, and “action-menu”. The first two contain the desired information, which for this case, will be the author of the comment, its URL channel, and the comment.
Now that we have an idea about the tags that contain the information we are looking for, we can use the WebDriver object to extract the data from those tags, the following methods can be used to achieve this.
The first thing we should do is to scroll down on the website, so we the comment section can fully be loaded, then we use the method find_elements_by_id to retrieve all the elements with the id “comment”. Next, we use a for loop to iterate over each comment. Finally, we use the find_element_by_* methods to move through the HTML structure and retrieve the information that we are looking for.
Conclusions.
In this post I explore only the surface of one of the applications for which we can use Selenium, since what, unlike other frameworks for web scrapping that only allows to load the static content, Selenium can be used to interact with websites using Python code similarly to the way we would do it using a browser.
In this case I used Selenium to execute JavaScript code to move through the page and load the comment section of a YouTube video. and extract the text content from the comments. This is a very naive implementation and the script I developed was just to show the potential of this library, but the wait times and the way we extract the comment can be optimized to use for real applications.
In future posts I will show how an entire application can be developed to not only extract the text from the comments but to analyze them using natural language processing (NLP). The script can be found in the following GitHub repository.
If you want to keep in contact with me and know more about this kind of content. I invite you to follow me on Medium and check my profile on LinkedIn
References
Don’t forget to give us your 👏 !




YouTube comment analysis. Part I. was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.