
Introduction
Have you ever wondered how techies build a chatbot? With the development of the python language, it has become simple with just a few lines of code. I’m trying to give some idea about how to build a simple chatbot using python and NLP which we come across in our daily interaction with any app/website.
Recently, the human interaction for most kinds of initial customer support is being handled by these chatbots which reduces an enormous amount of logs or complaints coming in the day-to-day lives for any product or service that we buy. The simple and repetitive queries are very well handled and it’s good to leave these tasks to robots and focus our human energy on more efficient work that adds value to the company.
There are two types of chatbots that we generally come across,
- Rule-Based Chatbot: It’s a decision tree-bots and use series of defined rules. The structures and answers are all pre-defined you are in control of the conversation.
- Artificial Intelligence Chatbot: It is powered by NLP(Natural Language Processing). It is more suited for complex kinds and a large number of queries.
Some applications of Chatbots:


Without wasting much time, let’s dive into the jupyter notebook and get our hands dirty with coding.
1. Import Required Libraries
Building a chatbot requires only three important libraries as follows,
nltk — Natural Language Tool Kit for natural language processing.
strings — To process strings in python
random — To randomly select the words or responses

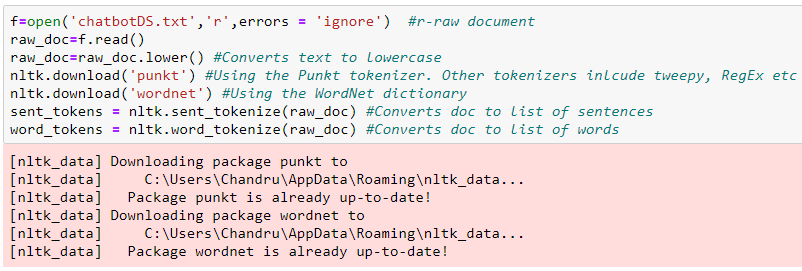
2. Import the Corpus
Courpus in simple terms means collection of texts(strings, words, sentences etc). It is the training data required for chatbot to learn. The corpus plays a very important role in deciding the responses. So whatever you want your chatbot to learn and respond has to put in a txt file and save it.
The NLTK data package includes pre-trained punkt tokenizer for english language so it is preferred over other tokenizers such as tweepy, RegEx etc.
Wordnet is a semantically-oriented dictionary of English included in NLTK library.
Corpus is the core of our chatbot from which we proceed further to data preprocessing where we handle text case and convert all the data input to either lower or upper case to avoid misinterpretation of words.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
3. Tokenization
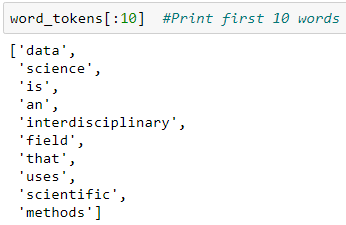
Tokenization is a process of converting a sentence into individual collection of words as shown below. The punkt tokenizer is used for this purpose.

Once we separate the sentences and words using tokenizer, let’s check if it is done correctly with the following codes.

4. Text Pre-processing
Lemmetization or Stemming is a process of finding similarity of words which are having same root(lemma) words. For example:

5. Generating Bag Of Words (BOW)
The process of converting words into numbers by generating vector embeddings from the tokens generated in the previous steps. For example
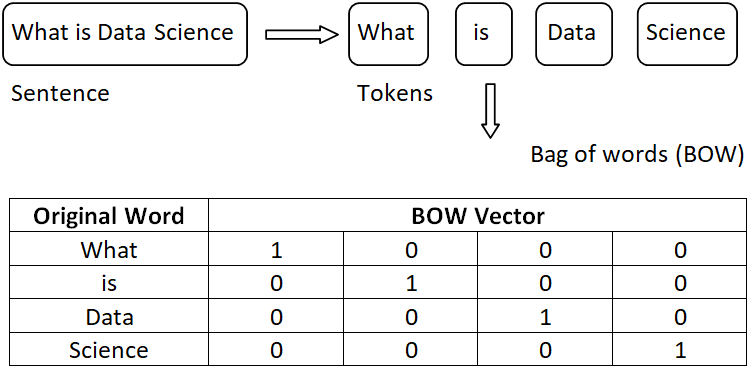
On top of this vector embeddings, one hot encoding is applied through which all the words are converted in 0’s and 1’s which will be used as input for the ML algorithms.

6. Defining the Greeting function

7. Response Generation function
Import two libraries that are important at this stage as follows:

Tfidf — Term frequency(tf) is used to count the frequeny of occurance of words in the corpus & how rare is the occurance of the word is identified by inverse document frequency(idf).
Once we have bag of words(BOW) converted into 0’s and 1’s the cosine_similarity function is used to produce normalized output so that machine can understand.
Next, we write a function for response generation so that after we provide certain data (corpus) to it and ask some questions, we get an answer. But in case if the user asks something which the chatbot don’t understand meaning tfidf==0 then the machine should respond accordingly as mentioned in the message.
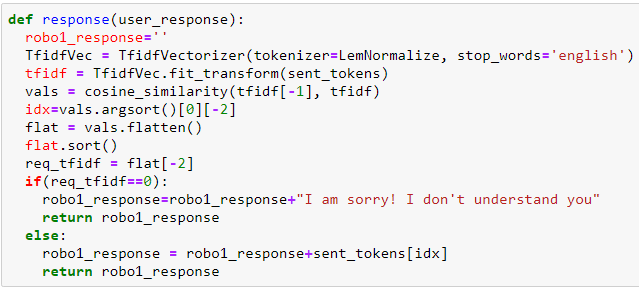
8. Defining conversation start/end protocols
In this section, as soon as the user greets, the chatbot will be able to respond back with the message & when the user says bye, it will quit. In between any questions related to our corpus will be responded back to the user which makes this chatbot interesting.
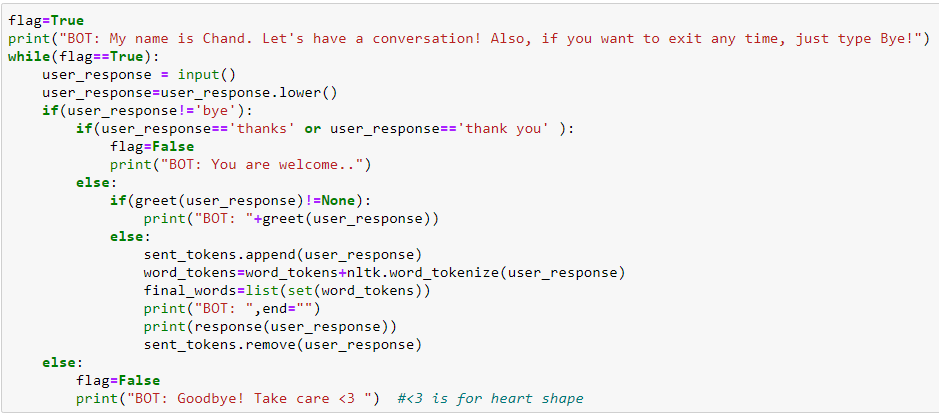
9. Chatbot queries and responses
Now, our simple chatbot is ready to respond to the user. Type in some inputs saying hi and it will respond with any of the greeting input by randomising it. When we ask any question and it will respond back to user with the related words and sentences which makes sense. Sample Chatbot interactions are shown below




Note: Since it is a simple chatbot, it will not answer some of the direct questions like what is data science and stuffs like that.
10. Conclusion
This is one of the most simple chatbots you can build with very few lines of code. Of course, if you want a more sophisticated chatbot then it all depends on the scale & vastness of the corpus which we give for training & the complexity of the code which helps the chatbot to learn and respond to the user questions.
Hope these baby steps helps my fellow friends and Data Science aspirants to dig deeper and build more complicated chatbots as per the requirement.
Final code for this project can be found at my GitHub repository.
Happy Learning!
11. References
- https://www.nltk.org/_modules/nltk/tokenize/punkt.html
- https://www.esparkinfo.com/in-depth-guide-of-chatbot.html
- https://en.wikipedia.org/wiki/Data_science
- https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
- https://www.greatlearning.in/academy/courses/261323/52827#?utm_source=share_with_friends
Don’t forget to give us your 👏 !




Building a simple Chatbot was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.