Welcome to part 1 of our tutorial on multimodal conversation design. Today we’ll take an in-depth look at what multimodal design is and learn more about its related components. Then in part 2, we’ll discuss best practices, use cases, and the outlook for the future.
From the moment we wake up, to when we’re about to go to bed, humans are absorbing information in a variety of ways. We combine multiple senses or modalities — sight, touch, taste, smell, sound — to draw singular conclusions. Our senses work together to build our understanding of the world and the challenges around us. With feedback and experience, they help reinforce certain behaviors and discourage the repetition of others. The more we process these combined or multimodal experiences, the more tangible and impactful they become.
Multimodal Conversation Design: a Human-Centric Approach
If multimodal is our natural human state, it stands to reason that multimodal design should be a natural outlook. Taking a human-centric approach, the multimodal design mixes art and technology to create a user experience (UX) that combines modalities across multiple touch points. Done well, this approach produces an interface that combines modalities in a way that sees them fit together organically to replicate an interpersonal human interaction. For example, using voice as an input mechanism married with a graphical user interface (GUI) as the output for the user.
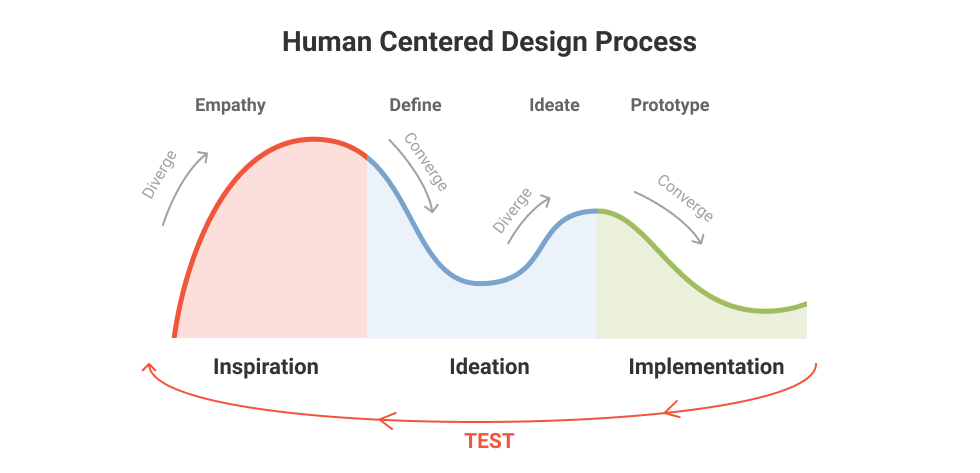
Traditionally we’ve thought about GUI and content design in silos; we even specialize designers and creatives along these lines. In a similar vein, modalities have also been siloed. Past processes would see the UX developed separately while content is developed and then the two are mashed together. In multimodal design, instead of building functionality one modality at a time, no input or output is treated separately or excluded. Developing all aspects of the UX together allows for the best modality for the context or circumstance to naturally emerge as the interaction unfolds.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
Context is Everything in Multimodal
What we sense, what information we need to understand and operate smoothly, and what we expect to do, all change depending on whether we’re having a conversation at a party, making dinner, driving a car, or reading a text message. The patterns of how these bundled expectations and abilities come together are called modalities. Having multiple sensory options is important when considering that all senses might not be simultaneously available, either temporarily or permanently. Providing inputs for all channels can increase accessibility and improve the reliability of the activity or information.
Multimodal Conversation Design: Inputs & Outputs
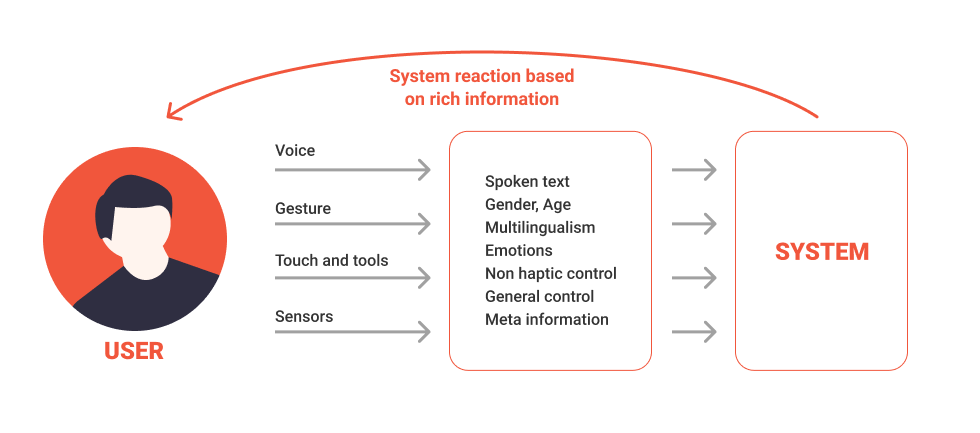
On a human level, communication isn’t limited to text and speech. We rely on a wide range of signals that include everything from hand gestures to eye movement to body language.
So why does conversation design continue to primarily focus on text and speech interactions? Lived experience clearly tells us we should not be limited to these modalities alone. For example, a chatbot should be capable of showing dynamic content (graphics, links, maps) to provide the best possible response. Some chatbots can also take commands via voice and then display the results as text or using a synthesized voice.
A similar approach that successfully meets people’s inclination towards multimodal interactions is voice search. This is the trend where we speak into our browser rather than type and receive our search results in return. In this respect, we can think of Google as the biggest single-turn chatbot in the world. Technology has evolved from searching with keywords and abbreviated phrases to the ability to search using natural language.
From a user’s perspective, a voice-controlled interface is appealing in its straightforward ease of use; the user wants something and simply asks for it. This is commonly referred to as the intent. The user then expects the system to come back with a relevant response, either as an action or information. Consuming information aurally requires more cognitive load from users, which suggests clarity and attention are more easily achieved through multimodal design.
In addition to text and speech, the most commonplace input modalities for interacting with a system include use of a mouse, keyboard, or touch/tap. Newer modalities, including gestural and physiological, are continuing to expand their use cases. A user should be able to provide information to a system in the most efficient and effortless way possible.
How is the optimal approach determined? Context. Stay tuned for part 2 where we’ll learn about contextualized best practices, use cases, and what the future might hold for multimodal conversation design.
Don’t forget to give us your 👏 !




Multimodal Conversation Design Tutorial: Overview and Key Elements was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.