
When we are working with computer vision tasks, there are some scenarios where the amount of data (images) is small or not enough to reach acceptable performance. In addition, dealing with image data and Convolutional Neural Networks (CNN) is expensive in terms of computational power.
Due to the issues aforementioned, in most cases it is convenient to use a technique called Transfer Learning, which consists of using models trained with millions of images, to improve the performance during the training process. We can implement this technique with Natural Language Processing (NLP) tasks, but instead of using pre-trained CNN models, for text classification, we are going to use pre-trained Word Embeddings.
Using Pretrained Word Embeddings
When we have so little data available to learn an appropriate task-specific embedding of your vocabulary, instead of learning word embeddings jointly with the problem, we can load embedding vectors from a precomputed embedding space that you know is highly structured and exhibits useful properties, that capture generic aspects of language structure.
Using Word Embeddings with TensorFlow for Movie Review Text Classification.
In this post, I am going to build a tweet classifier to show how we can implement transfer learning with Embedding Layers so we can improve the learning process.
Use case: Tweet Classification
The problem we are trying to solve is related to text classification and sentiment analysis, in this case we have a dataset that contains tweets labeled according to the sentiment they express.
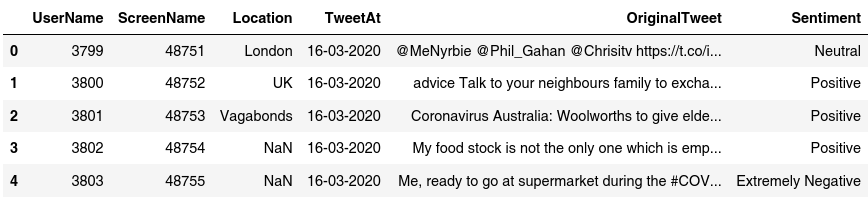
In the figure shown above, we can see the columns in our dataframe, for this specific task we are just going to use the columns OriginalTweet and Sentiment
Clean tweets.
Texts coming from tweets are usually “noise” in terms of language use, in tweets we might encounter things like links, abbreviations, hashtags, HTML code, emojis, and other things that are made just for human communication so we need to pay special attention to the cleaning process. The cleaning process consists of the following steps:
- Remove links
- Replace abbreviations.
- Replace emojis.
- Turning lower all the words.
- Remove symbols and pictographs.
- Remove punctuation signs.
Trending Bot Articles:
2. Automated vs Live Chats: What will the Future of Customer Service Look Like?
4. Chatbot Vs. Intelligent Virtual Assistant — What’s the difference & Why Care?
After applying these steps we obtain text data we can implement the rest of the text processing tasks that are usual when we are dealing with this kind of problem.

Above, we can see the same tweet before and after the cleaning process. This process helps to improve the learning process of word embeddings and it is necessary for every NLP task.
Sentiment Analysis.
The tweets in our dataset were tagged manually according to 5 categories. The categories are:
- Positive
- Extremely Positive
- Neutral
- Negative
- Extremely Negative
The data distribution looks like:
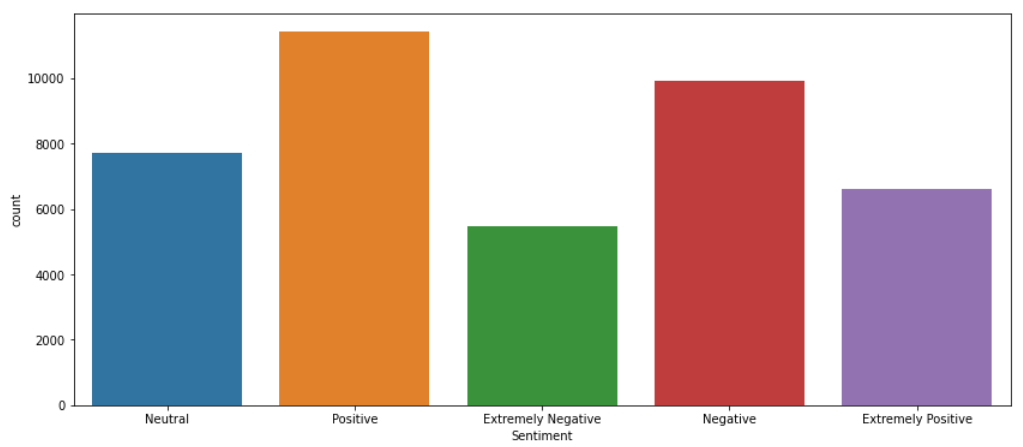
To facilitate the process, I am going to simplify the problem and not worry about the intensity of the sentiment, so I will put together the instances that belong to the classes Positive and Extremely Positive and do the same with the tweets with labels Negative and Extremely Negative resulting just three classes:
- Positive
- Neutral
- Negative
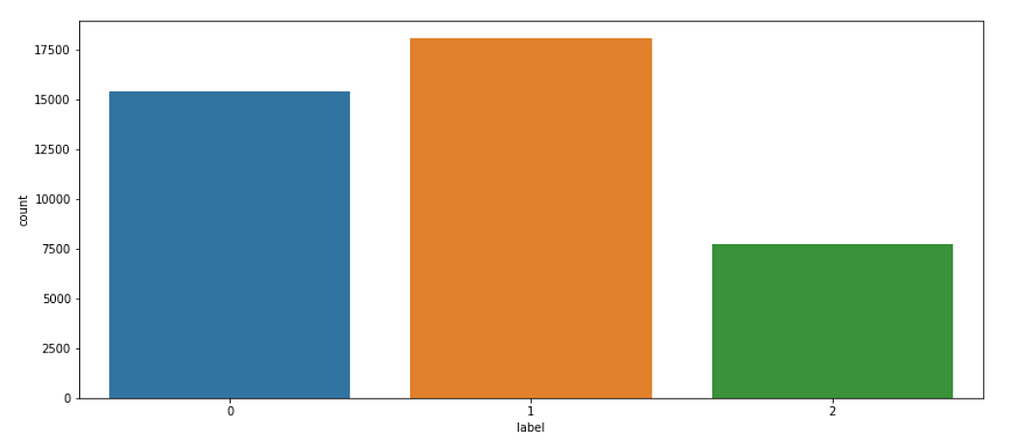
In the figure above we can see the data distribution of the new labels. The labels 0, 1, and 2 correspond to the categories negative, positive, and neutral. It can be seen that the problem we are dealing with is represented by an unbalanced dataset. This is, the number of instances belonging to each class is different.
Movie Review Text Classification Using scikit-learn
Text Processing.
The first step I am going to perform over the data is called Tokenization, This process is about reducing each tweet up to the minimum unit of information, these units of information are called Tokens, we can Tokenize or tweets are character level or word level, in this case, I will Tokenize the tweets at the word level, TensorFlow brings a tool to Tokenize text data automatically.
After the Tokenization process, we need to convert the tweets into sequences, we can do this using a method from the class Tokenizer and become the text data into numeric sequences. Let’s see an example to be clear.
The Tokenizer generates an index for the words in the text, the code shown above generates the next word index:
{'to': 1,
'data': 2,
'i': 3,
'am': 4,
'trying': 5,
'show': 6,
'how': 7,
'implement': 8,
'transfer': 9,
'learning': 10,
'with': 11,
'word': 12,
'embeddings': 13,
'but': 14,
'every': 15,
'project': 16,
'that': 17,
'involves': 18,
'requires': 19,
'some': 20,
'pre': 21,
'processing': 22,
'tasks': 23,
'for': 24,
'example': 25,
'we': 26,
'need': 27,
'clean': 28,
'the': 29,
'text': 30,
'and': 31,
'perform': 32,
'other': 33,
'processes': 34,
'like': 35,
'tokenization': 36}
The Tokenizer class allows us to know other aspects related to the data like the word count, but for know let’s pay attention to the fact that now each word can be represented with a number (index). Thanks to this we can represent every line in our little dataset as a sequence, to do that we just use the method texts_to_sequences

In the figure shown above, we can see how each line of text in the list is represented by a numeric sequence. But there is a problem with this approach, neural networks can only receive as input, sequences with equal lengths, to solve this problem we can use TensorFlow to pad or truncate the sequences in such a way all the sequences have the same length.

By default, the method pad_sequences implement “pre-padding” and “pre-truncating”, this is, if one sequence is longer than the maximum length allowed (maxlen), the sequence will be truncated removing values from the beginning of the sequence. On the other hand, if the sequence is shorter than the maximum length, then it will be padded by putting values at the beginning of the sequence. The default value for padding sequences is 0.
Building the model
There are various precomputed databases of word embeddings that we might use in a Keras Embedding layer. One of them is Global Vectors for Word Representation (GloVe), which was developed by Stanford researchers in 2014. Its developers have made available precomputed embeddings for millions of English Tokens, obtained from Wikipedia data and Common Crawl data. In this example, I am going to use a precomputed embedding from 2014 English Wikipedia. It’s an 822 MB zip file called glove.6B.zip
The first thing that we need to do is parse the text file, we can reach this using the code shown below.
The code shown above will print the following results:
Found 400000 word vectors.
Now we have a dictionary where each key is the word and each value is the vector coefficients. The next step is to create a word embedding matrix adapted to our dataset (tweet dataset). This means, find the vector that corresponds to each word in our vocabulary after the cleaning and Tokenization processes. This will be a matrix of shape (max_words,embedding_dim) The next code is in charge of that.
Let’s create a sequential model using Keras, the first layer of this model will be the embedding layer, then I am going to use a LSTM layer followed by a GlobalMaxPool1D, which downsample the input representation (LSTM output) by taking the maximum value over the time dimension. Finally, we have two dense layers.
Up to this point, we haven’t used the transfer learning technique yet. The next step is to set the weights of our embedding layers, which corresponds with the embedding matrix created before. In addition, we mustn’t change these weights during the learning process, so we must freeze the embedding layer to avoid changing the weights during the training stage.
To train the model, I am going to implement two callbacks to improve the training process, “reducing on plateau” will reduce the learning rate by a 0.2 factor when there is no improvement. I will also implement early stopping to avoid overfitting due to over training.
How to Use Callbacks with TensorFlow and Keras
Using class weights.
In addition, we can use weights proportional to the number of instances in each class to letting the model know what classes need “more attention” reducing the problems due to the unbalanced dataset that we are using. We can use the parameter called “class_weight” to do this.
Model evaluation
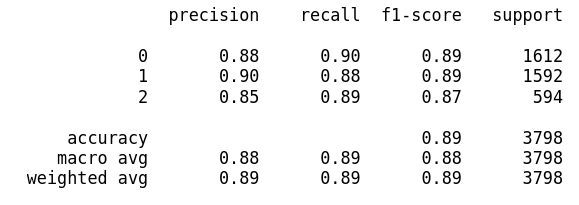
In the report shown above, the labels 0, 1, and 2 correspond to the categories negative, positive and, neutral, respectively. The model has an accuracy of around 90 %, as we can see, the label 2 or neutral category has the worst performance.
Conclusion
In this article, we have learned how to implement transfer learning in NLP tasks, as we have seen, TensorFlow and Keras allow us to use this technique easily. You can see more details related to the code in my GitHub repository.
I am passionate about data science and like to explain how these concepts can be used to solve problems in a simple way. If you have any questions or just want to connect, you can find me on Linkedin or email me at manuelgilsitio@gmail.com
References.
- TensorFlow for text processing.
- Francois Chollet, Deep Learning with Python. New York:Manning Publications Co. 2018
- Kaggle: Coronavirus Tweets NLP Text Classification
Don’t forget to give us your 👏 !




Using Transfer Learning with Word Embeddings for Text Classification Tasks was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.