Review Analysing Application using NLP — Part 1

In my previous article, I talked about how machines communicate with humans. In there, I have mentioned the NLP — Natural Language Processing. NLP did a significant role in communication with computers and humans. Today I am going to implement a Simple Review Annalysing Application using NLP and python. I used PyCharm IDE for coding.
Review Analysing Application is a Text Classification application. This article has four sections. they are
- Import dataset
2. Cleaning dataset
3. Create bag_of_words Model
4. Create a Classification Model
5. Test Accuracy

1. Import the dataset
#CSV dataset vs TSV dataset
CSV means Comma-Separated Values, and TSV means Tab-Separated Values. Simply if the dataset is in .csv format, the values in the dataset are separated by comma(“,”). If the dataset is in .tsv format, the values in the dataset are separated by a tab. Usually, for NLP, we are getting .tsv form. Because in NLP, we are dealing with sentences. In sentences, there have most commas. See the example text,
Loved it...friendly servers, great food, wonderful and imaginative menu.
In this example, we have more commas. So if we used .csv, the separated values might be incorrect. But in here no tabs. Therefore we usually get the dataset format .tsv for the NLP.
#Importing the dataset
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('DataSet/review_dataset.tsv', delimiter ='t', quoting = 3)
To import the dataset, I used pandas library’s read_csv function. I set the delimiter as tab because the dataset is in .tsv format. And also, I set quoting to 3 because I want to ignore double quotes also.
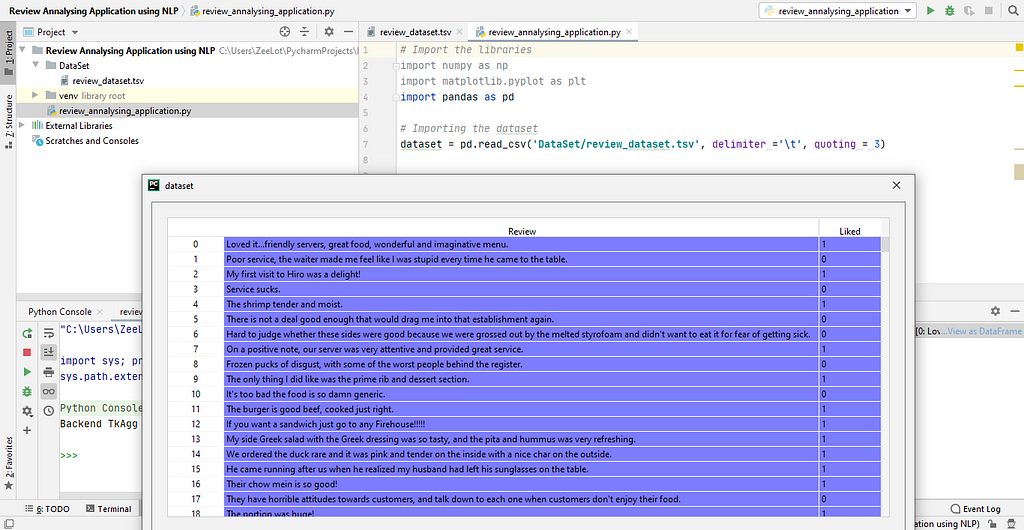
Here I have 1000 reviews. That dataset has two columns. They are Review and Liked or Not. The review section has the String text given by someone. And Liked or Not section has a Boolean value about his satisfaction.
Trending Bot Articles:
1. How Chatbots and Email Marketing Integration Can Help Your Business
2. Clean the dataset
Firstly I clean one review. And then I apply that method to all reviews.
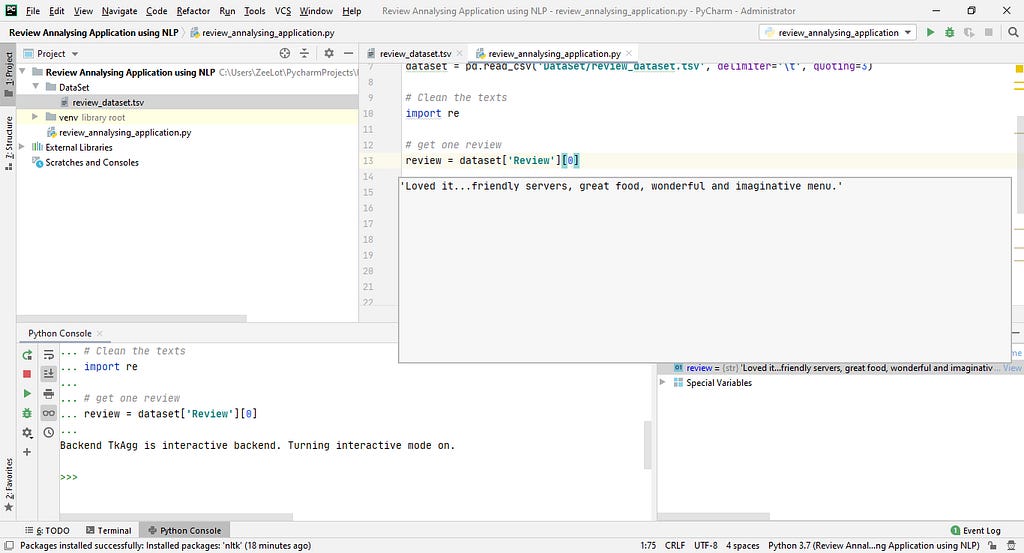
# get one review
review = dataset['Review'][0]
For clean the reviews, I use a library called re.
# Remove all things except letters
For the review analysing I want only words. I don’t want any punctuation marks or any numbers. Therefore I remove all unwanted stuff. And I store that sentence again in the review variable. For that, I used sub function in re library.
# remove all things except letters
import re
review = re.sub('[^a-zA-Z]', ' ', review)
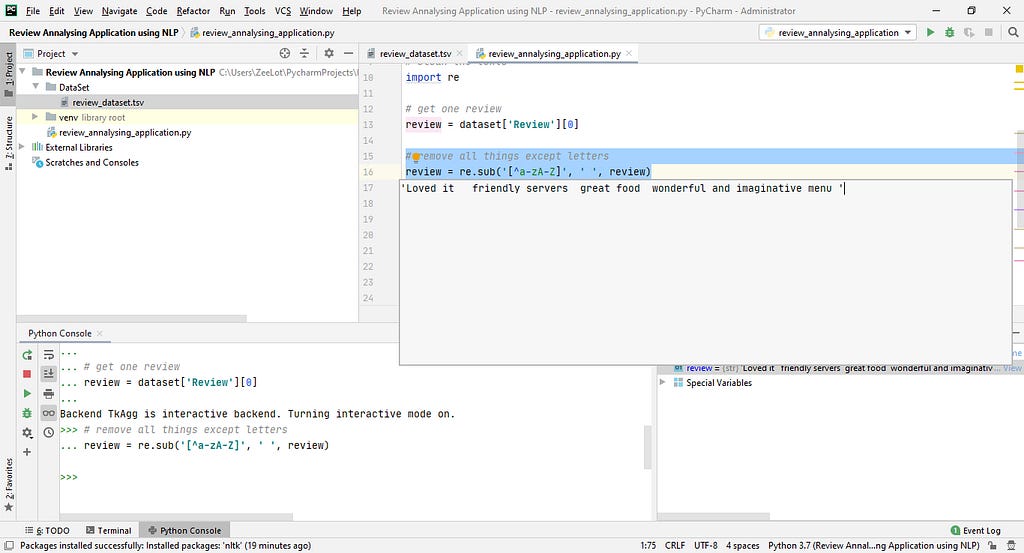
Now you can see there haven’t any punctuations or numbers.
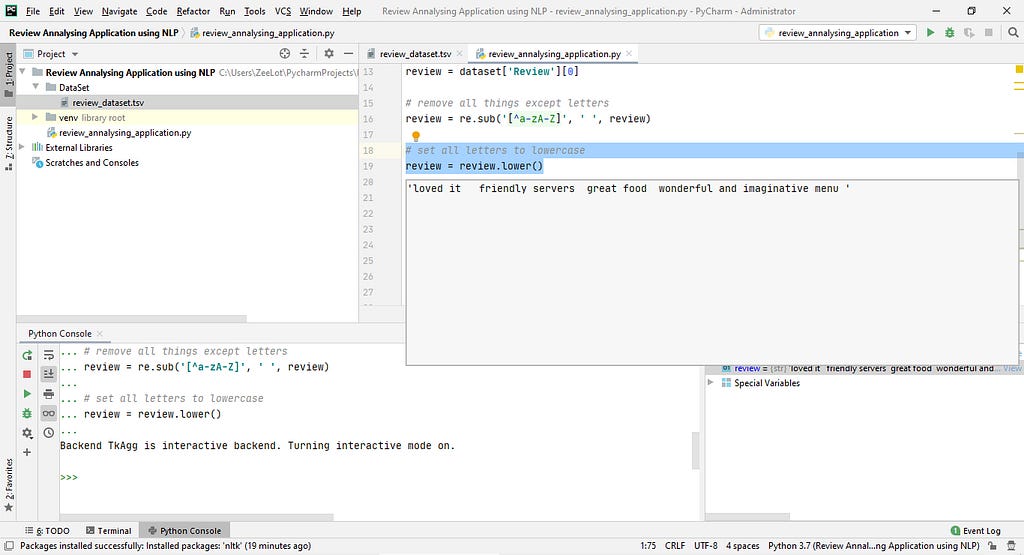
# Set all letters to lowercase
and then I change all letters to lowercase. because I want to number of words in the bag_of_words
# set all letters to lowercase
review = review.lower()
# Convert the string to a list
I convert the string value to a list because another step I’m going to remove non-significant words. For that, I use a for a loop. therefore I convert string to a list
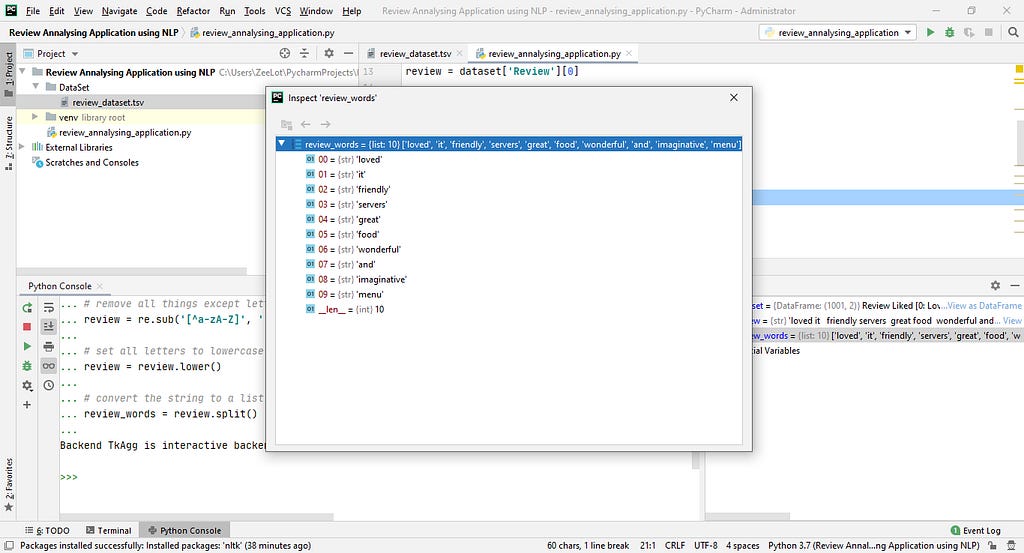
# convert the string to a list
review_words = review.split()
# Remove non-significant words
In the review, there have words to unwanted for the review analysing purpose. Such as I, am, are, this, that… So I also remove those words. For that, I used the nltk — Natural Language Toolkit package. In nltk have a list named ‘stopwords’. Using that word list, I can remove non-significant words.
# remove non significant words
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
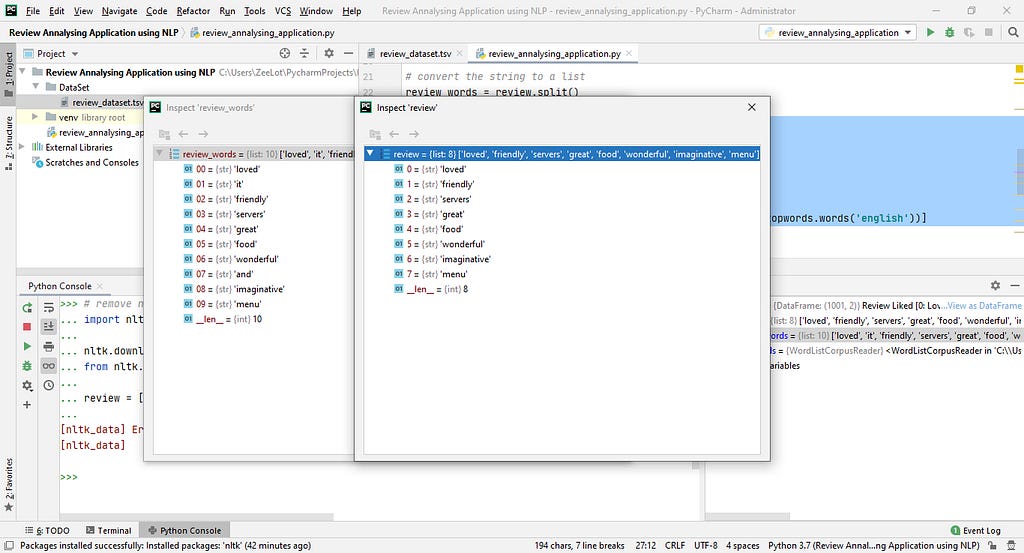
review = [word for word in review_words if not word in set(stopwords.words('english'))]
# Stemming => taking the root of the words
we are ding stemming because we want to remove unwanted words from the bag_of_words. Directly stemming means taking the origin of the word. As an example, I get a sentence,
Loved it...friendly servers, great food, wonderful and imaginative menu.
In this sentence have a word named ‘loved’. But this is not the root of that word. The origin of that word is ‘love’. ‘love/loved/loving’ these all words are given the same sense about the review positive or negative. Therefore we don’t want those all words. We can use only the root word for that. If we use the origin word only, our bag_of_words also will be small. We use stemming to reduce the number of words in the bag_of_words.
Simply we,
loved/loves/loving/love => love
for that, I used PorterStemmer in nltk.stem.porter library.
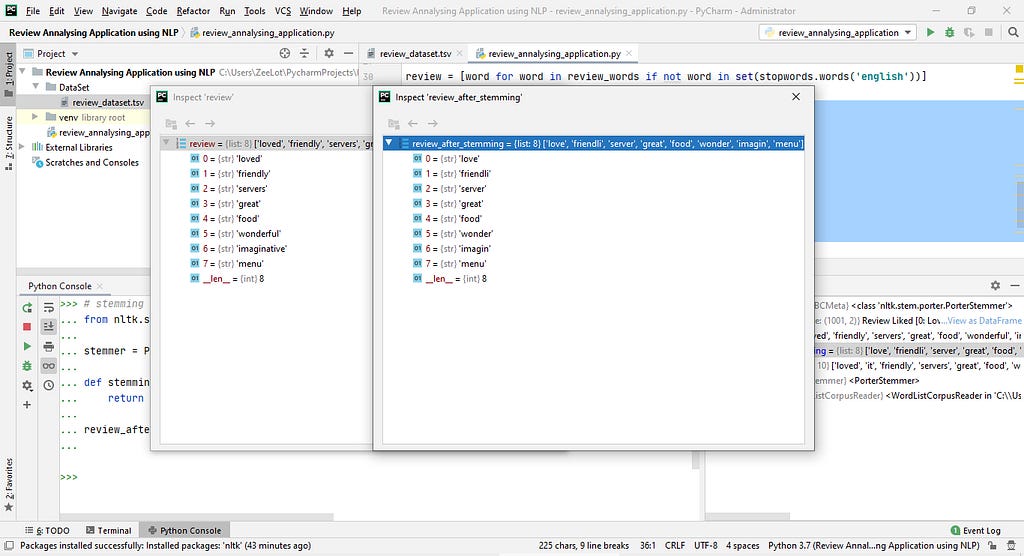
# stemming => taking the root of the words
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
def stemming(word):
return stemmer.stem(word)
review_after_stemming = [stemming(word) for word in review]
# Convert list into a string
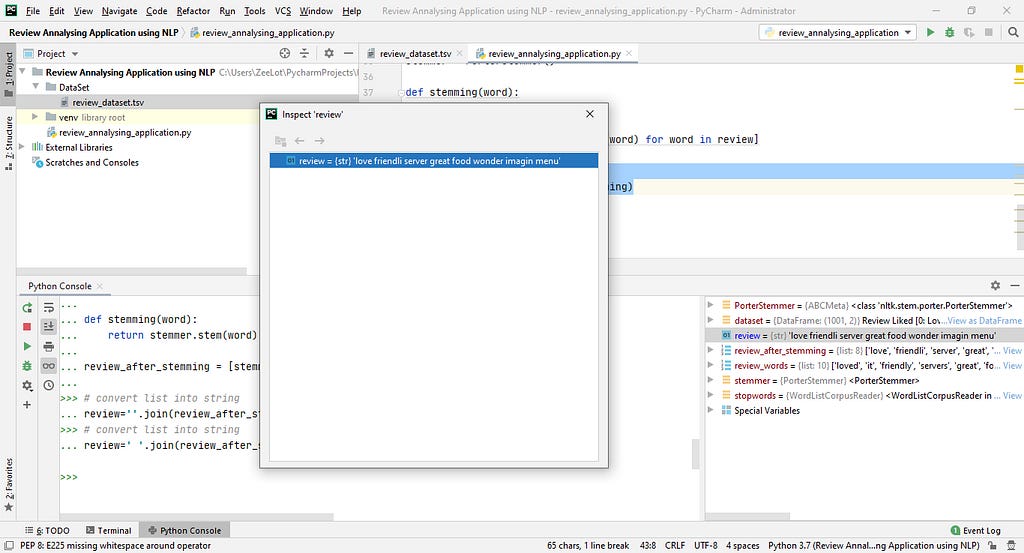
Now the cleaning process is over. Therefore I again convert that list to a string.
# convert list into string
review = ' '.join(review_after_stemming)
# Doing this method to all reviews
Now I’m doing that cleaning process to all reviews.
# doing this method to all reviews
corpus = []
for i in range(0,1000):
review = dataset['Review'][i]
review = re.sub('[^a-zA-Z]', ' ', review)
review = review.lower()
review_words = review.split()
review = [word for word in review_words if not word in set(stopwords.words('english'))]
stemmer = PorterStemmer()
review_after_stemming = [stemming(word) for word in review]
review = ' '.join(review_after_stemming)
corpus.append(review)
Now 1 – Import dataset and 2 – Cleaning dataset is done. We will see other sections in Review Analysing Application using NLP — Part 2.
Don’t forget to give us your 👏 !




Review Analysing Application using NLP — Part 1 was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.