For the last 4 years I’ve been building a chatbot in IBM Watson and for four years I’ve been plagued with the same three issues.
- How do I know if new ground truths I’m adding aren’t just creating more confusion in the model?
- How do I know what the best way to split my intents so they’re well defined?
- How do I understand what customers are asking at scale?
None of these challenges are unique to IBM Watson like all off the shelf SaaS products in the Chatbot space the convenience of having a simple interface and not needing to be an expert in NLP or Chatbots to get started does leave a lot of the behind the scenes workings with an air of mystery about them, that you’re not going to be able to fully optimise for if you’d built an NLP pipeline yourself. One thing Watson does provide which not all platforms do is a Confidence score which is a number between 0 an 1 representing the similarity between data inside of your intents ground truths (Example question and data) vs what the customer asked. One important thing to note is people mistakenly believe that if your top scoring intent is 85% then that means all the other intents confidences will add up to 15% combined. This isn’t right each intent is appraised and scored independent of one another so it’s possible for Intent 1 to have a score of 95% and Intent 2 a score of 93% this is important and we’l come back to this later. Watson will actually allow us to return the top 10 Intents and their scores if we wanted to expand the scope of our investigation but we’re just sticking to the winner and runner up.

The first step in finding an answer to these problems was to collect prime customer given unambigous examples of questions that customers have used and should always return the expected answer and do so with at least a moderate degree of confidence. I look through my logs and find what I think are good examples of customer questions and put them in a CSV file. I want to repeatedly run these questions as I’m tweaking my ground truth data. It’s important to use customer questions as they’re the best source of data even if they’re not always the most succinct way of asking a question. There’s often a vast difference between how an Subject Matter Expert summarises an example of a good question and how a customer asks it your model should be trained for your users not your in house SMEs.
When collecting data it’s important to decide for yourself what intent should be triggered and not just the intent that was triggered by the system. Taking your labels from the system is almost certainly going to return the same labels defeating the purpose of this exercise!
I always focus on a few main metrics to understand the model I’ve created and how close to disaster I potentially am.
- How clearly my model matches my customers questions which is denoted by getting the right intent and when it doesn’t get the right intent what intent is it getting.
- How Confident it is in getting the right intent by it’s Confidence score.
- How well defined my datat is based on what the second highest scoring intent was and it’s how close it is to the best scoring.
Trending Bot Articles:
4. How intelligent and automated conversational systems are driving B2C revenue and growth.
I run these questions in bulk and repeatedly using the messaging API this allows me to generate a comprehensive report time and time again, using the same questions provides me with a good milestone to get a much deeper understanding of my model. I can know that when I’ve added new content and intents that my old intents are still working and if there are changes in the scores then I’m able to appreciate how everything has changed and reflect at the full picture rather than getting frustrated as question after question starts to fail.
This post is to accompany a Github notebook and to provide context on why these metrics are useful https://github.com/CallumK24/Watson-Degradation-Tester
Metric 1 Correct Response.
The simplest metric of the three. Did the prediction for what Intent should be triggered actually get triggered?
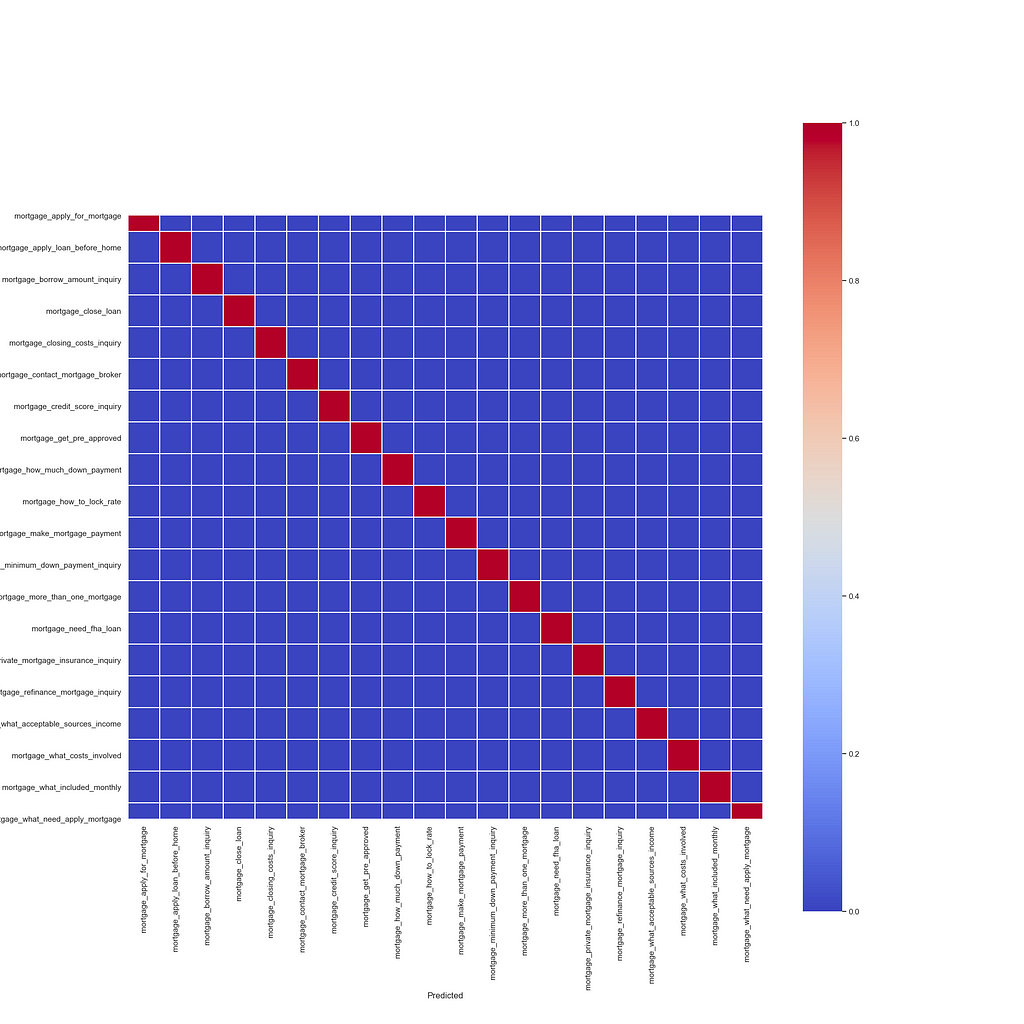
If I’m encountering conflicts where I frequently think a question should be triggering Credit Card statement but it’s frequently triggering an intent called Order New Card then that’s a sign that my ground truths need some work.
You can turn this into a percentage and calcualate how often your prime examples generate the correct answer. (This should be high this data is hand picked to be accurate)
Using a simple confusion matrix the Examples that matched vs the unmatched examples can be clearly shown like the below to remove the manual sorting and filtering, giving a quick visual reference when you have a large number of intents. You can quickly identify poorly performing intents on as the predicted are on the Y axis and the Actual are shown on the X axis.
The below example shows all intents match up as expected with no outliers in this sample data. Poorly performing intents will be a less solid red following the pattern through. It’s important to make sure you have at least one example per intent to compare against otherwise you’ll have data that doesn’t perfectly line up.
A question mapping to its correct intent is the most important metric, and the one that you want to keep rerunning as even though you’re not looking at the final answer provided by your bot, the likelihood is that it’s not a problem with your model that you can’t foresee it’s a problem with your logic and node triggers which you can.
Metric 2 Average Confidence per Intent.
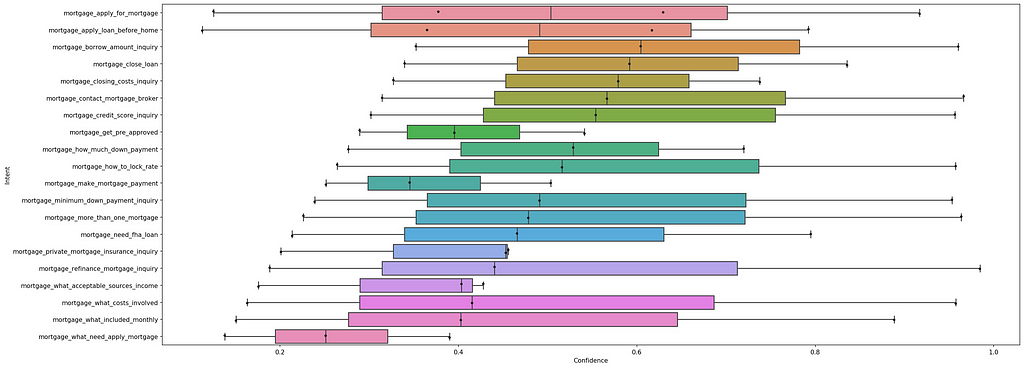
A more complex metric but nearly as important is if my prediction matches the outcome then what is the confidence score for that one question and what is the average across all matching intents and questions this frames an intent in a new way. It allows you to see an intent and it’s examples in terms of their average rather than just on a question by question basis.
You can take the average of Matched and Unmatched confidences, when you’re right you want to be right in a big way getting a high average confidence and when you’re wrong you want to have a lower average confidence. If you see a lot of high confidence unmatched results for a specific intent then this is an area that you need to focus on by either merging the intents or deleting poorly performing ground truths.
With my results I created a simple box and whisker to visualise the differences in performance for each intent. Previously I was just creating a table of averages but it completely lacks the context of the average vs the distribution which when trying to get an overview is something that you’ll need.
Metric 3 How well defined the top intent is from it’s nearest competitor.
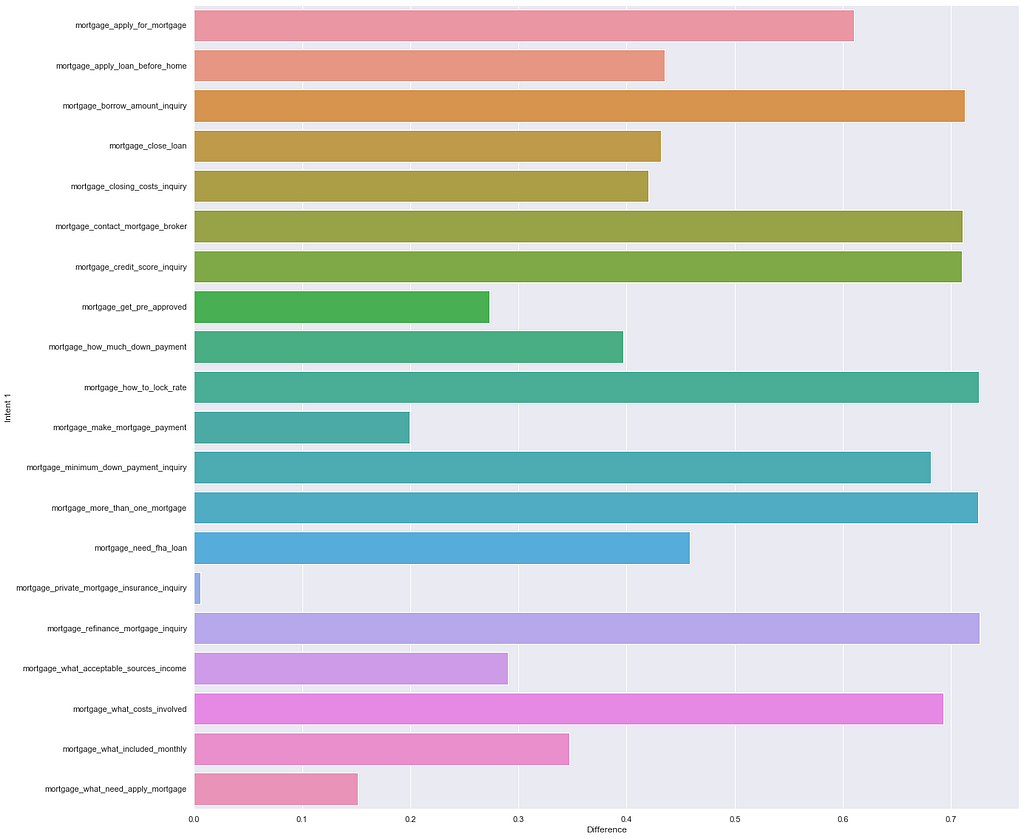
Confidence scores in Watson Assistant are generated between 0 and 1. Let’s pretend that pretend for an example there’s only 2% between the top scoring intent and it’s nearest competitor and both are at the top of the range at 92% and 90% It shows that while you may have gotten a match between Expected and Actual your model isn’t comfortably confident that it truly understands the difference between Intent A and Intent B
We’re not matching Intent A vs a specific Intent only it’s next closest match, we can use the data to do this manually there’s just not a succinct and simple way of showing this data across the entire dataset consistently if you have over 150 intents it can be incredibly messy to visually represent.
Each intents average score difference between that intent and the next top scoring intents. The higher the better.
Pulling it all together
These metrics while quite basic by themselves are powerful when combined together have enabled me to actually fix problems and see where there are gaps in my understanding of my own model. Working with a tool that’s as easy to use as Watson is great but if I want to make sure I’m extracting all the value I can then I need to make sure that the data I’m using and how I’m choosing to structure my data is optimised for the algorithm that is itself a trade secret.
Being able to look at how well defined a customer question is and how well defined it is from it’s nearest neighbour allows me to confidently say that the model isn’t confused with where I’ve allocated questions to my intents and that the customer data I’m testing is accurate enough to be confidently answered by my ground truths.
Being able to look at the averages per intent allows me to understand at scale what my average performance is for an intent and what my problem areas are I can use my confusion matrix to see where my intents are getting mixed up and I can use my bar horizontal bar chart to look how well defined each intent is.
This is by no means the definitive guide and won’t be appropriate for everyone but it’s a good place to start and adapt to suit to your own needs.
Don’t forget to give us your 👏 !




IBM Watson Assistant model monitoring and improvements. was originally published in Chatbots Life on Medium, where people are continuing the conversation by highlighting and responding to this story.